Python, YAML, and Kubernetes — The Art of Mastering Configuration
A practical guide to simplifying Kubernetes configuration management with Python and YAML

Last week, I faced a seemingly daunting task: updating numerous Kubernetes YAML files for a large-scale application with multiple microservices.
The challenge was to modify environment variables and resource limits across these microservices to accommodate changes in our application’s configuration, such as pointing to a new database server and adjusting specific settings.
Rather than going through the tedious and error-prone process of manually editing each file, I turned to a more efficient solution.
With just a few lines of Python code and the PyYAML library's help, I could read, modify, and write the Kubernetes configuration files quickly and accurately, ensuring consistent changes across all the affected microservices.
In this article, we will explore the basics of YAML, the powerful capabilities of the PyYAML library, and how Python can be leveraged to simplify working with Kubernetes configuration files.
We’ll also provide a step-by-step guide on creating your own Python script to automate parsing and updating YAML files, demonstrating the true potential of combining Python and YAML in managing complex configurations.
As always, you can find all the source code examples in this GitHub repository, which is readily accessible for your reference.
Understanding YAML and its role in DevOps and Kubernetes
YAML, “YAML Ain’t Markup Language,” is a human-readable data serialization format commonly employed in configuration files and for data exchange between programming languages with varying data structures.
Due to its readability and simplicity, YAML has become the go-to choice for numerous DevOps services and tools for pipeline configuration and setup.
Examples of services and tools that rely on YAML for configuration include:
- Ansible
- Docker Compose
- Kubernetes
- Amazon Web Services (AWS)
- CircleCI
- GitHub Actions
- Azure DevOps build and releases pipelines
By utilizing YAML, these services and tools facilitate a more streamlined and user-friendly approach to configuration management and deployment processes.
YAML also plays a critical role in Kubernetes, serving as the primary format for defining and managing Kubernetes resources and configurations.
Kubernetes utilizes YAML files to declaratively specify the desired state of various resources within the cluster, such as deployments, services, and config maps.
Python Libraries for Working with YAML
Several libraries can be used to parse, manipulate, and generate YAML data when working with YAML files in Python.
These libraries easily handle YAML data structures within Python applications, facilitating seamless integration with other tools and services.
This section will cover some of the most popular and widely used Python libraries for working with YAML.
PyYAML
PyYAML is a widely-used Python library that allows you to parse, create, and manipulate YAML data. It provides methods to load YAML data from a file or a string, representing the data as native Python data structures like dictionaries, lists, and scalars.
PyYAML also offers methods to convert Python data structures back to YAML format and write them to a file or a string.
ruamel.yaml
ruamel.yaml is another popular Python library for working with YAML data, designed to be a more modern and feature-rich alternative to PyYAML. It supports YAML 1.2 and is compatible with many Python versions. The library provides methods for loading, dumping, parsing, and emitting YAML data while preserving comments, formatting, and order.
While PyYAML and ruamel.yaml are the most commonly used libraries for working with YAML in Python, you may encounter other libraries that offer additional features or cater to specific use cases. When choosing a library, consider factors such as ease of use, performance, compatibility, and community support to ensure it meets your requirements.
One of the key differences between ruamel.yaml and PyYAML is that ruamel.yaml supports the YAML 1.2 specification, while PyYAML only supports YAML 1.1.
This article will use the PyYAML library to work with YAML files due to its broad support and widespread usage within the Python community. PyYAML has become a popular choice for developers, providing a simple and intuitive interface for parsing, creating, and manipulating YAML data.
While it may not support the latest YAML 1.2 specification, PyYAML remains a reliable and well-established library that caters to many use cases, making it an excellent choice for our purposes.
Reading and Parsing Kubernetes YAML Files with Python
Let’s harness the power of Python and PyYAML to read and parse our first Kubernetes YAML file. We will work with an example Pod specification containing an NGINX container and utilize the pretty print function to display the parsed YAML as native Python objects.
Here’s a glimpse of the example NGINX Pod YAML file we’ll be using:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx
name: nginx
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}And the Python script to read and parse the YAML file can be seen below. The load_and_print_yaml function takes a filename as an argument, reads the YAML data from the file, and pretty-prints the parsed content.
import yaml
import pprint
def load_and_print_yaml(filename):
with open(filename, "r") as file:
data = yaml.safe_load(file)
pprint.pprint(data)
def main():
example_file = "./example-k8s-files/nginx.yaml"
load_and_print_yaml(example_file)
if __name__ == "__main__":
main()The script provided earlier produces the following output. As demonstrated, the safe_load function from the PyYAML library reads and parses the YAML file, converting it into a collection of nested Python dictionaries.
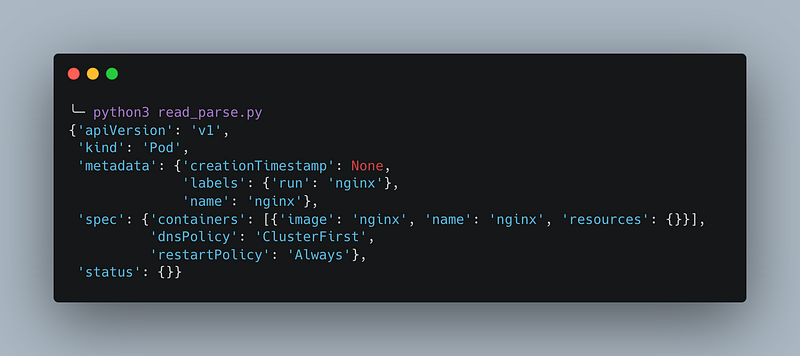
To access a single field, such as the image field of the Pod, you use the syntax as can be seen below. This code navigates through the nested Python dictionaries, accessing the "spec" field, then the "containers" field (which is a list, so we use the index 0 to get the first container), and finally the "image" field of the Pod.
image = data["spec"]["containers"][0]["image"]
print("Image: ", image)In the upcoming section, we will read a Kubernetes YAML file, parse its contents, modify it, and then save the changes to the disk.
Modifying Kubernetes Configurations Using Python and PyYAML
In this section, we will use a Kubernetes example that closely aligns with the scenario described in the introduction. This will help illustrate how the concepts discussed earlier can be applied practically.
We have a Kubernetes deployment YAML file specifying our application's environment settings and CPU resource requirements.
We need to increase the logging level to investigate some problems with the application. However, this will also increase the application’s CPU usage, so we need to update the CPU request to ensure that the application has sufficient resources.
To make these changes, we will modify the deployment YAML file by changing the LOG_LEVEL environment variable to 2 and updating the CPU request from 500m to 750m. After adjusting the file, we will save the updated YAML file to disk."
The YAML file is included below for reference.
apiVersion: apps/v1
kind: Deployment
metadata:
name: workflow-encoder
spec:
replicas: 3
selector:
matchLabels:
app: workflow-encoder
strategy:
type: Recreate
template:
metadata:
labels:
app: workflow-encoder
spec:
containers:
- name: workflow-encoder
image: workflowencoder:3.5.1
env:
- name: LOG_LEVEL
value: "1"
resources:
requests:
cpu: 500m
memory: 1024Mi
limits:
cpu: 8000m
memory: 2524MiThe Python script for reading, changing, and writing the YAML file is below. This code defines a function modify_yaml_file that modifies a Kubernetes deployment YAML file by changing the LOG_LEVEL environment variable and the CPU request.
The YAML file is read into memory using the yaml.safe_load() function. It loads the YAML data into a Python dictionary. It then modifies the YAML data by accessing and updating the appropriate keys in the dictionary.
Finally, the function writes the modified YAML data to a new file using the yaml.safe_dump() function.
import yaml
def modify_yaml_file(source_path, destination_path, log_level, cpu_request):
with open(source_path, 'r') as input:
yaml_data = yaml.safe_load(input)
containers = yaml_data['spec']['template']['spec']['containers']
# Modify the LOG_LEVEL
containers[0]['env'][0]['value'] = str(log_level)
# Modify the CPU request
containers[0]['resources']['requests']['cpu'] = str(cpu_request)
with open(destination_path, 'w') as output:
yaml.safe_dump(yaml_data, output)
def main():
source_path = './example-k8s-files/encoder.yaml'
destination_path = './example-k8s-files/encoder_changed.yaml'
log_level = 2
cpu_request = '750m'
modify_yaml_file(source_path, destination_path, log_level, cpu_request)
if __name__ == '__main__':
main()In the previous example, we modified existing values within the Kubernetes YAML file. Additionally, it is possible to introduce new sections to the YAML file. In our following example, let’s illustrate this by adding a non-existent resources section, which includes CPU and memory requests, to the YAML file.
We will continue to use the same YAML file from the previous example but with the resources section removed for this demonstration.
apiVersion: apps/v1
kind: Deployment
metadata:
name: workflow-encoder
spec:
replicas: 3
selector:
matchLabels:
app: workflow-encoder
strategy:
type: Recreate
template:
metadata:
labels:
app: workflow-encoder
spec:
containers:
- name: workflow-encoder
image: workflowencoder:3.5.1
env:
- name: LOG_LEVEL
value: "1"The Python script for adding the resources section is below. The add_resources_section function adds the resources section to the specified YAML data.
It inputs the YAML data, the desired CPU and memory requests, and limits. The function then iterates through the containers defined in the YAML and adds the resources section with the specified requests and limits for CPU and memory to each container.
import yaml
def read_yaml_file(filename):
with open(filename, 'r') as file:
yaml_data = yaml.safe_load(file)
return yaml_data
def add_resources_section(yaml_data, cpu_request, memory_request, cpu_limit,
memory_limit):
containers = yaml_data["spec"]["template"]["spec"]["containers"]
for container in containers:
container["resources"] = {
"requests": {
"cpu": cpu_request,
"memory": memory_request
},
"limits": {
"cpu": cpu_limit,
"memory": memory_limit
}
}
return yaml_data
def write_yaml_file(filename, yaml_data):
with open(filename, 'w') as file:
yaml.safe_dump(yaml_data, file)
def main():
source_file = './example-k8s-files/encoder_without_requests.yaml'
destination_file = './example-k8s-files/encoder_with_requests_limits.yaml'
cpu_request = '200m'
memory_request = '512Mi'
cpu_limit = '500m'
memory_limit = '1Gi'
yaml_data = read_yaml_file(source_file)
modified_data = add_resources_section(yaml_data, cpu_request,
memory_request, cpu_limit,
memory_limit)
write_yaml_file(destination_file, modified_data)
if __name__ == "__main__":
main()PyYAML is helpful in reading and writing YAML files in Python and can also be utilized to validate Kubernetes YAML files. The following section will demonstrate how to validate a directory full of YAML files using PyYAML.
Validating YAML files
Typically, when creating a resource in Kubernetes using kubectl, the Kubernetes API server validates the submitted YAML and notifies you of any issues.
However, you can also create a Python script utilizing PyYAML to validate all your Kubernetes YAML files. The example below does just that by iterating over every YAML file in a folder and validating each one. If a file fails validation, the script outputs the file’s name.
The validate_yaml_file function performs the core validation task. It employs the safe_load function to attempt to load the YAML file. If successful, it returns None; otherwise, it returns the file name and the associated error message. PyYAML generates the error message with details indicating the location of the error within the YAML file.
import os
import yaml
import sys
def get_yaml_files_in_directory(directory):
yaml_files = []
for root, _, files in os.walk(directory):
for file in files:
if file.endswith('.yaml') or file.endswith('.yml'):
yaml_files.append(os.path.join(root, file))
return yaml_files
def validate_yaml_file(file_path):
try:
with open(file_path, 'r') as file:
yaml.safe_load(file)
return None
except yaml.YAMLError as error:
return f"Error in {file_path}: {error}"
def validate_all_yaml_files(files):
invalid_files = []
for file in files:
error_message = validate_yaml_file(file)
if error_message:
invalid_files.append((file, error_message))
return invalid_files
def main():
if len(sys.argv) < 2:
print("Usage: python validate_yaml.py <directory>")
sys.exit(1)
directory = sys.argv[1]
yaml_files = get_yaml_files_in_directory(directory)
invalid_files = validate_all_yaml_files(yaml_files)
if invalid_files:
print("\nThe following YAML files are invalid:")
for file, error_message in invalid_files:
print(f"- {file}: {error_message}")
sys.exit(2)
else:
print("All YAML files are valid.")
if __name__ == "__main__":
main()As we’ve explored the process of validating YAML files using Python, it’s worth noting that there’s always room for improvement in performance.
The following section will investigate optimizing Python and YAML performance to ensure our validation script runs efficiently and effectively.
Optimizing Python and YAML performance
Improving the performance of PyYAML can be achieved through various approaches, such as using faster parsers or libraries, caching, and parallel processing. Here are some suggestions:
Use the libyaml library
PyYAML can use the libyaml library for faster parsing and emitting. To enable this feature, you need to have the libyaml library installed and then install PyYAML with support for it:
pip install pyyaml --global-option="--with-libyaml"
After installation, you can use the C-based loaders and dumpers for faster performance.
yaml.load(file, Loader=yaml.CSafeLoader)
yaml.dump(data, file, Dumper=yaml.CSafeDumper)Cache the parsed YAML files
If you repeatedly parse the same YAML files, consider caching the parsed content to avoid re-parsing. You can use Python’s built-in functools library to implement caching.
from functools import lru_cache
@lru_cache(maxsize=None)
def load_yaml(file_path):
with open(file_path, 'r') as file:
return yaml.safe_load(file)Parallel processing
You can improve performance by processing them in parallel if you have many YAML files to validate. Depending on your use case and system resources, you can utilize Python’s concurrent.futures library to achieve parallel processing with either threads or processes.
Here’s an example of using ThreadPoolExecutor for parallel validation:
from concurrent.futures import ThreadPoolExecutor
def validate_all_yaml_files(files):
invalid_files = []
with ThreadPoolExecutor() as executor:
results = executor.map(validate_yaml_file, files)
for file, error_message in zip(files, results):
if error_message:
invalid_files.append((file, error_message))
return invalid_filesAs we conclude this final example on enhancing performance, we have reached the end of the article. Let’s wrap up with a brief recap of the key topics we’ve covered throughout the discussion in the Conclusion.
Conclusion
YAML has emerged as an integral part of modern DevOps practices and container orchestration platforms like Kubernetes.
Its simplicity, readability, and adaptability make it an ideal choice for configuration management in various tools and services.
Python, a versatile and powerful programming language, offers libraries like PyYAML and ruamel.yaml, making working with YAML data simple and efficient.
This article has provided insights into how Python and YAML can be leveraged to create, modify, and validate Kubernetes configurations.
We have explored how PyYAML can parse, modify, and generate YAML data for Kubernetes resource management. Additionally, we have demonstrated how to validate and optimize the performance of YAML configurations using Python.
By understanding and utilizing the power of Python and YAML, developers can create more streamlined and maintainable configurations for their DevOps pipelines and Kubernetes clusters.
Embracing these techniques will empower developers to manage and deploy applications effectively, ensuring the success and longevity of their software projects.
You can find all the source code examples in this GitHub repository.



