Python Persistence Perfected
Optimizing data storage with the repository and unit of work patterns

Python’s increasing popularity has led to the development of larger and more complex projects. This growth has sparked developers’ interest in high-level software design patterns, like those prescribed by domain-driven design (DDD).
Yet, implementing these patterns in Python can be challenging.
This hands-on series aims to provide Python developers with practical examples. The focus is on proven architectural design patterns to manage application complexity.
This opening article of the series will delve into persistent storage management using the Repository and Unit of Work (UoW) patterns.
All the examples featured in this article can be conveniently accessed in the accompanying GitHub repository.
Understanding the repository and unit of work patterns
The Repository and Unit of Work patterns are architectural patterns that help manage and organize data storage in a way that promotes efficient, maintainable, and scalable code.
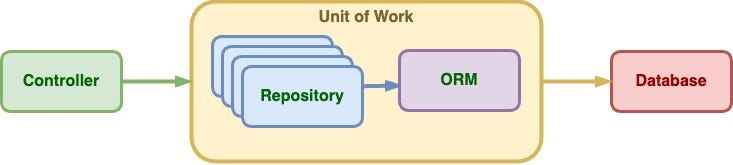
Understanding the repository and unit of work patterns is essential for developers seeking to implement a robust, maintainable, and efficient data access layer in their applications.
The repository pattern abstracts the underlying data store and provides a consistent interface for querying and managing data entities. It enables developers to write testable and decoupled code by separating the data access logic from the business logic.
On the other hand, the unit of work pattern coordinates multiple repositories to achieve transactional consistency by keeping track of changes made to the data and committing those changes as a single transaction.
This pattern ensures that all data operations within a business transaction succeed or fail together, thereby maintaining data integrity. These patterns form a powerful combination for handling complex data manipulation scenarios in large-scale applications.
However, it is important to remember that these patterns may only be suitable for some solutions, as they can introduce additional complexity. In smaller applications, employing the repository and unit of work patterns might be overkill, leading to increased development effort without significant benefits.
Repository pattern
The Repository pattern is a well-documented way of working with a data source. In the book Patterns of Enterprise Application Architecture, Martin Fowler describes a repository as follows:
A repository performs the tasks of an intermediary between the domain model layers and data mapping, acting similarly to a set of domain objects in memory. Client objects declaratively build queries and send them to the repositories for answers. Conceptually, a repository encapsulates a set of objects stored in the database and operations that can be performed on them, providing a way closer to the persistence layer.
The Repository pattern abstracts how data is stored, retrieved, and manipulated. It is an intermediary between the business logic and the data access layer.
By abstracting data access, it promotes a cleaner and more organized codebase. It separates concerns, making it easier to maintain and test the application.
Another advantage of using the Repository pattern is that it allows developers to change the underlying data storage implementation without affecting the business logic.
To be honest, in my 25 years of professional development experience, I have only encountered the need to change the underlying data storage implementation once.
This arose from a demand for better database performance, prompting a switch from a relational database to a time series database.
However, due to the significant differences in the storage APIs between these two types of databases, we still had to modify the repositories to accommodate the new system.
While the Repository pattern provides abstraction, in cases like this, it may not eliminate adjustments when making changes to the storage infrastructure.”
Additionally, the pattern encourages using a consistent data access API across the application, improving code readability and reducing the likelihood of errors.
So, even if you don’t switch storage systems often, adopting the Repository pattern can still lead to long-term advantages in the development process.
Unit of work pattern
As a developer, the Unit of Work pattern is incredibly useful in managing a series of operations as a single atomic transaction.
It ensures that all the operations are completed successfully or not at all. This helps you maintain data consistency across multiple operations.
When working with transactions involving multiple repositories, the Unit of Work pattern shines. It coordinates these repositories and manages their interactions within the context of a unified transaction.
By implementing the Unit of Work pattern in your projects, you can simplify transaction management and maintain data integrity across various repositories, making your job easier and more efficient.
What we will be building
The figure presented below illustrates the components we will construct throughout this article. Additionally, it serves as a guide for organizing the source code, featuring distinct folders for use cases, adapters, and so on.
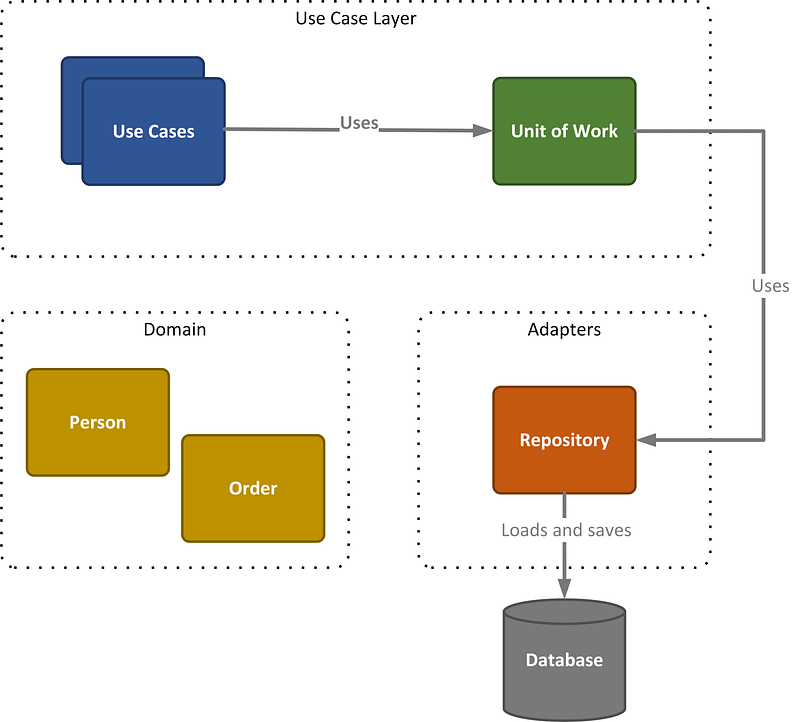
We will start with the repository, progressively advance to the unit of work, and ultimately conclude with implementing a singular use case.
The Order and Person objects serve as straightforward domain objects. By utilizing the Python @dataclass decorator, available in Python 3.7 and later versions, the init and repr methods are automatically generated, simplifying the creation and representation of these objects.
Implementing the Repository
First, we will introduce the Repository pattern, which functions as an abstraction for data storage, retrieval, and manipulation, as a liaison between business logic and the data access layer.
We created a BaseRepository class to form the groundwork for all repositories.
Despite Python’s absence of native interface construction, we utilized the ABC (Abstract Base Class) library and its abstractmethod decorator to simulate interface-like functionality, thus maintaining a uniform structure for our repositories.
By leveraging TypeVar, this base class enables the creation of specific repositories for domain objects, for example, PersonRepository(BaseRepository[Person]).
The BaseRepository consists of four methods: add, update, delete, and get_by_id.
from typing import TypeVar, Generic
from abc import ABC, abstractmethod
T = TypeVar('T')
class BaseRepository(ABC, Generic[T]):
"""A base class for repositories"""
@abstractmethod
def add(self, item: T):
"""Add a new item to a repository"""
raise NotImplementedError()
@abstractmethod
def update(self, item: T):
"""Update an existing item in the repository"""
raise NotImplementedError()
@abstractmethod
def delete(self, item_id: int):
"""Delete an existing item from a repository"""
raise NotImplementedError()
@abstractmethod
def get_by_id(self, item_id: int) -> T:
"""Retrieve an item by its id"""
raise NotImplementedError()To persist the data, we use an SQLite database. Therefore, we implement an SQLitePersonRepository that derives from the BaseRepository. Check out the SQLitePersonRepository below.
Instead of using an Object Relational Mapper (ORM) like SQLAlchemy, we directly execute SQL statements to implement the repository, providing a more hands-on approach to database interactions.
Later, we will demonstrate how the repository can be swapped out for an in-memory repository or one that utilizes SQLAlchemy, showcasing the flexibility of our approach.
A separate _create_table is called from the class's constructor that generates the Person table if it does not exist.
class SQLitePersonRepository(BaseRepository[Person]):
def __init__(self, connection):
self.connection = connection
self._create_table()
def _create_table(self):
cursor = self.connection.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS persons (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER NOT NULL
)
""")
self.connection.commit()
def add(self, person: Person):
cursor = self.connection.cursor()
cursor.execute(
"INSERT INTO persons (name, age) VALUES (?, ?)",
(person.name, person.age)
)
person.id = cursor.lastrowid
def get_by_id(self, person_id: int) -> Optional[Person]:
cursor = self.connection.cursor()
cursor.execute("SELECT id, name, age FROM persons WHERE id=?",
(person_id,))
row = cursor.fetchone()
if row:
return Person(row[1], row[2], row[0])
return None
def update(self, person: Person):
cursor = self.connection.cursor()
cursor.execute(
"UPDATE persons SET name=?, age=? WHERE id=?",
(person.name, person.age, person.id)
)
def delete(self, person_id: int):
cursor = self.connection.cursor()
cursor.execute("DELETE FROM persons WHERE id=?", (person_id,))As a reference, we’ve also developed the SQLiteOrderRepository, which closely resembles the SQLitePersonRepository. If you want to examine this class, please explore the file in the GitHub repository for further details.
Implementing the Unit of Work
The Unit of Work pattern manages transactions when working with multiple repositories. As a result, the UnitOfWork class has access to all the repositories involved, including the SQLitePersonRepository and SQLiteOrderRepository in our example.
The UnitOfWork class incorporates Python’s context manager to efficiently handle the commits and rollbacks of database transactions. Consequently, this enables using the Python with statement when employing the class.
To create a context manager, you implement two special methods in your class: __enter__ and __exit__.
class UnitOfWork:
def __init__(self, connection: BaseConnection,
person_repository: BaseRepository[Person],
order_repository: BaseRepository[Order]):
self.persons = person_repository
self.orders = order_repository
self.connection = connection
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
if exc_type:
self.rollback()
else:
self.commit()
def commit(self):
self.connection.commit()
def rollback(self):
self.connection.rollback()In our UnitOfWork class, we have designed it to commit the outstanding transaction if no exceptions occur. If an exception does arise, the transaction is rolled back instead.
Using the Unit or Work through a Use Case
A Use Case class is the final component for utilizing our Unit of Work. We create a CreatePersonAndOrderUseCase that uses the UnitOfWork to insert a Person and Order record into the database within a single transaction, ensuring data consistency.
class CreatePersonAndOrderUseCase:
def __init__(self, unit_of_work: UnitOfWork):
self.unit_of_work = unit_of_work
def execute(self, person: Person, order: Order) -> Tuple[Person, Order]:
with self.unit_of_work as uow:
uow.persons.add(person)
order.person_id = person.id
uow.orders.add(order)
return person, orderThe execute method takes two arguments, a person object (an instance of the Person class) and an order object (an instance of the Order class). The method returns a tuple containing the Person and Order instances.
Inside the execute method, a with statement creates a context for the UnitOfWork object, ensuring proper transaction management.
When the with block is exited, the UnitOfWork context manager commits the transaction if no exceptions were raised or rolls back the transaction if an exception occurred.
Finally, the execute method returns the person and order objects.
Executing the CreatePersonAndOrderUseCase
Having developed the CreatePersonAndOrderUseCase, we can now demonstrate its functionality by creating a small command-line interface (CLI) application.
The implementation of main.py below executes the CreatePersonAndOrderUseCase, which inserts a new Person and their associated Order record into our SQLite database.
To establish the database connection, we define a context manager called create_database_connection, this time using the @contextmanager decorator. This approach simplifies the database connection management throughout the code.
The remainder of the code sets up instances of the required classes, enabling dependency injection as needed. Finally, the use case is executed, inserting the Person and Order objects into the database.
@contextmanager
def create_database_connection():
db_connection = sqlite3.connect("./db/data.db")
try:
yield db_connection
finally:
db_connection.close()
with create_database_connection() as conn:
connection = SQLiteConnection(conn)
person_repository = SQLitePersonRepository(conn)
order_repository = SQLiteOrderRepository(conn)
unit_of_work = UnitOfWork(connection, person_repository,
order_repository)
create_use_case = CreatePersonAndOrderUseCase(unit_of_work)
new_person = Person(name="John Doe", age=30)
new_order = Order(person_id=None, order_date="2023-04-03",
total_amount=100.0)
person, order = create_use_case.execute(new_person, new_order)Dependency injection
Although we haven’t demonstrated unit tests for the individual components, the structure of our solution facilitates the easy addition of such tests.
This is primarily due to our use of dependency injection, which provides instances of dependencies as external inputs instead of creating them directly within a class.
This approach reduces tight coupling between classes, promoting modularity and making the codebase more adaptable and easier to maintain.
class UnitOfWork:
def __init__(self, connection: BaseConnection,
person_repository: BaseRepository[Person],
order_repository: BaseRepository[Order]):
self.persons = person_repository
self.orders = order_repository
self.connection = connectionThe UnitOfWork class you saw earlier accepts instances of SQLitePersonRepository and SQLiteOrderRepository through its constructor, injecting the dependencies into it.
Dependency injection offers several advantages:
- Enhanced code reusability: Since classes are no longer responsible for creating their dependencies, they become more focused on their core responsibilities, improving reusability.
- Easier testing: By injecting dependencies, it becomes simpler to replace real dependencies with mock objects during testing, facilitating unit testing and isolating specific components.
- Increased flexibility: Dependency injection allows for swapping out one implementation of a dependency with another without modifying the dependent class, enabling greater adaptability and easier updates or upgrades.
Dependency injection results in a more robust, flexible, and maintainable codebase that can better adapt to evolving requirements and updates.
The following article will look at Python dependency injection in further detail.
Swapping the repositories
As the saying goes, “the proof of the pudding is in the eating,” so let’s put our solution to the test by switching to different types of repositories and evaluating the required changes.
First, we’ll implement an in-memory repository, which can be particularly useful for testing.
Next, we’ll incorporate SQLAlchemy as an ORM within our repository, eliminating the need to write SQL code manually, as currently demonstrated in the SQLitePersonRepository.
This will showcase the flexibility and adaptability of our solution when working with various repository implementations.
In memory repository
An in-memory repository stores data in memory using data structures such as arrays, lists, or dictionaries rather than persisting it to an external storage system.
This repository type is particularly useful for unit testing and integration testing. It enables quick and easy data access without the overhead of interacting with a database or other storage systems.
We opted to use a dictionary internally for our in-memory repository, as it greatly simplifies the implementation of the repository methods.
As demonstrated in the new InMemoryOrderRepository class. Dictionary operations allow for more efficient and concise code when implementing the repository.
class InMemoryOrderRepository(BaseRepository[Order]):
def __init__(self):
self.orders = {}
def add(self, order: Order):
self.orders[order.id] = order
def get_by_id(self, order_id: str) -> Optional[Order]:
return self.orders.get(order_id)
def update(self, order: Order):
self.orders[order.id] = order
def delete(self, order_id: str):
self.persons.pop(order_id, None)Similarly, we’ve developed an InMemoryPersonRepository with a dictionary to store Person objects. This approach streamlines the implementation of the repository methods.
We also need to modify the SQLiteConnection class, which inherits from BaseConnection and serves as an interface for the commit and rollback methods of the underlying connections.
For an InMemoryConnection, the rollback and commit methods are essentially no-ops, as the data is stored in memory and not persisted to an external storage system.
The implementation of the InMemoryConnection is shown below.
class InMemoryConnection(BaseConnection):
def commit(self):
pass
def rollback(self):
passWith the introduction of these three new classes, we can now configure our use case to utilize in-memory storage. The CreatePersonAndOrderUseCase, UnitOfWork, and the Person and Order objects remain unchanged, demonstrating the flexibility of our solution.
To execute the use case with in-memory storage, we create instances of InMemoryPersonRepository and InMemoryOrderRepository, instead of the SQLitePersonRepository and SQLiteOrderRepository.
These instances are then injected into the UnitOfWork in the same manner as before, as shown in the updated code below. This highlights the ease of switching between different repository implementations.
connection = InMemoryConnection()
person_repository = InMemoryPersonRepository()
order_repository = InMemoryOrderRepository()
unit_of_work = UnitOfWork(connection, person_repository,
order_repository)
create_use_case = CreatePersonAndOrderUseCase(unit_of_work)
new_person = Person(name="John Doe", age=30)
new_order = Order(person_id=None, order_date="2023-04-03",
total_amount=100.0)
person, order = create_use_case.execute(new_person, new_order)
print(person)
print(order)SQLAlchemy repository
The SQLAlchemy repositories, as the name suggests, utilize the SQLAlchemy library to streamline the management of database interactions.
By leveraging the capabilities of SQLAlchemy’s Object Relational Mapper (ORM), these repositories provide an elegant and efficient way to handle database operations within the application.
The SQLAlchemy repositories offer an advantage over the SQLite repositories because there is no need to write explicit SQL queries.
The new class, SQLAlchemyPersonRepository, contains some differences from the SQLite or in-memory versions, as demonstrated below.
Instead of a connection, the constructor gets an instance of the SQLAlchemy Session class. This class contains the functionality to interact with the ORM.
Pay close attention to the self.session.flush() in the add method. Since a person's 'id' field is set to auto-increment, the flush method is necessary. By doing so, the 'id' field is automatically populated with the newly generated identifier for the person.
class SQLAlchemyPersonRepository(BaseRepository[Person]):
def __init__(self, session: Session):
self.session = session
def add(self, person: Person):
self.session.add(person)
# flush() is needed to get the id of the person
self.session.flush()
def update(self, person: Person):
self.session.merge(person)
def delete(self, person_id: int):
person = self.session.query(Person).get(person_id)
if person:s
self.session.delete(person)
def get_by_id(self, person_id: int) -> Optional[Person]:
return self.session.query(Person).get(person_id)Similarly, we’ve developed an SQLAlchemyOrderRepository. See the GitHub repository for the details.
To effectively utilize an ORM like SQLAlchemy, some additional configuration is required. Specifically, you need to inform SQLAlchemy about the desired structure of your database tables and the mapping between your classes and the database tables.
To accomplish this, we will implement a function called create_tables_and_mappers that outlines the structure of the tables and creates the necessary mappers, bridging the gap between the classes and their corresponding database tables.
def create_tables_and_mappers(metadata):
person_table = Table(
'person', metadata,
Column('id', Integer, primary_key=True),
Column('name', String),
Column('age', Integer)
)
order_table = Table(
'order', metadata,
Column('id', Integer, primary_key=True),
Column('person_id', Integer, ForeignKey('person.id')),
Column('order_date', String),
Column('total_amount', Float)
)
mapper_registry = registry()
mapper_registry.map_imperatively(Person, person_table)
mapper_registry.map_imperatively(Order, order_table)With these new classes and methods, we can now configure our use case to utilize SQLAlchemy. Again, the CreatePersonAndOrderUseCase, UnitOfWork, and the Person and Order objects remain unchanged.
The difference in main lies in the create_database_session method, which, similar to the SQLite version, employs a context manager. This method handles the configuration of SQLAlchemy-specific components, including creating the database and session.
To execute the use case with the SQLAlchemy ORM, we create instances of SQLAlchemyPersonRepository and SQLAlchemyOrderRepository, instead of the SQLitePersonRepository and SQLiteOrderRepository.
These instances are then injected into the UnitOfWork in the same manner as before, as shown in the updated code below. This again highlights the ease of switching between different repositories.
@contextmanager
def create_database_session():
Base = declarative_base()
create_tables_and_mappers(Base.metadata)
engine = create_engine("sqlite:///./db/data.db")
Base.metadata.create_all(engine)
SessionFactory = sessionmaker(bind=engine)
session = SessionFactory()
try:
yield session
finally:
session.close()
with create_database_session() as session:
connection = SQLAlchemyConnection(session)
person_repository = SQLAlchemyPersonRepository(session)
order_repository = SQLAlchemyOrderRepository(session)
unit_of_work = UnitOfWork(connection, person_repository,
order_repository)
create_use_case = CreatePersonAndOrderUseCase(unit_of_work)
new_person = Person(id=None, name="John Doe", age=30)
new_order = Order(person_id=None, order_date="2023-04-03",
total_amount=100.0)
person, order = create_use_case.execute(new_person, new_order)
print(person)
print(order)Unit testing
While this article does not delve into unit testing, as the focus is on discussing the Repository and UnitOfWork patterns, a collection of unit tests has been developed and made available in the accompanying GitHub repository for your reference and exploration.
Source code structure
The source code of the GitHub repository is structured as follows.
Adapters — This directory hosts various repository implementations (e.g., SQLitePersonRepository, InMemoryPersonRepository) to interface with external systems or libraries.
DB — This directory manages the database, including automatically generated components and any related configuration files
Domain — This directory holds the core business logic, encompassing domain entities, value objects, and associated rules and validations.
Tests — This directory contains unit and integration tests to ensure the application’s functionality and reliability.
Use Cases — This directory encapsulates the application’s use cases (e.g., CreatePersonAndOrderUseCase), outlining the interactions between the domain layer and external systems or actors.
Conclusion
This article serves as the first piece in a series dedicated to exploring various proven architectural design patterns in Python aimed at managing complexity.
This article examined the Repository and UnitOfWork patterns in Python, highlighting their ability to streamline database interactions and enhance application development by effectively handling complex tasks.
By adopting these patterns, we effortlessly transitioned from an SQLite repository to an in-memory repository and subsequently to a repository utilizing SQLAlchemy, showcasing the flexibility and adaptability provided by these design patterns.
While unit testing was not explicitly discussed in this article, a suite of tests is available in the GitHub repository for further examination.
Adopting these patterns can significantly improve the organization, maintainability, and performance of your Python applications that require persistent storage and simplify transitions between different storage solutions.
However, it’s crucial to recognize that implementing these patterns introduce additional complexity to your system. You must carefully evaluate your situation and determine whether these patterns are necessary. Simpler alternatives might be better suited.
This GitHub repository contains all the examples discussed in this article.



