How to Tackle Scalability With CQRS using Python and FastAPI
Exploring Command Query Responsibility Segregation (CQRS) in Streamfinity’s Python-based FastAPI to resolve performance challenges

A fine day dawned over the bustling tech department at Streamfinity, where the whirring of computers hummed in harmony with the keystrokes of Devon, their trusty DevOps engineer.
The usual rhythm of the day was interrupted when his phone buzzed with an urgent message. The sender? Harper, the company’s no-nonsense CTO.
“Devon,” the message read, her sharp tone reverberating through the pixels, “we have a problem”.
“The Streamfinity API is on its knees under a tsunami of requests. Most of them, predictably, are for movie lists and details. The strain on our servers is mounting, and our current approach is not scaling well. We need a game-changer.”
Devon stared at the message, his mind buzzing with the intensity of the problem. The architecture of Streamfinity’s API was a thing of beauty.
It was a fine-tuned symphony of domain models and SQLModel intricacies, orchestrating all interactions with the database. But as he sifted through the flood of requests, a nagging question surfaced: Was the symphony playing the wrong tune for read operations?
Devon pondered over the situation. The API was in a constant tug of war between maintaining the barrage of read requests and managing concurrent write operations.
It was akin to asking a juggler to add a flaming torch to his act, all while balancing on a unicycle.
Suddenly, a light bulb moment struck Devon. What if the cycle could be replaced with a more stable base? What if the read operations were separated from the write operations?
This could evenly distribute the weight of requests and create room for scalability.
With newfound excitement, Devon researched this concept and stumbled upon Command Query Responsibility Segregation (CQRS). This design pattern distinctly separates the read model (queries) from the write model (commands).
Armed with this knowledge, Devon approached Harper with his plan.
“Harper, I think I’ve got something. What if we implement CQRS?”
Intrigued and recognizing the potential of this solution, Harper gave him the nod. And so, they embarked on the challenging journey to redesign the heart of Streamfinity API using CQRS and Python.
Through this article, we invite you to step into the shoes of Devon, Harper, and the Streamfinity team.
Join us on an adventure filled with victories, roadblocks, and insightful lessons, as we journey down the path of integrating CQRS in Python within Streamfinity.
Feel free to explore our prototype in this GitHub repository, where you’ll find instructions in the README file. These instructions will guide you through installation and help you get the system up and running.
Chapter 1: The Current Reality

The story of Streamfinity is one marked by innovative solutions and groundbreaking technology. As a digital rights management (DRM) startup, Streamfinity catered to various content providers' digital movie encoding needs.
In-house, they boasted a sleek, cutting-edge player and a robust REST API that streamlined the services and made them accessible to customers. However, the mantle of creating client-facing websites was left for the customers to shoulder.
The reaction was ecstatic as Streamfinity unveiled its brand new REST API, developed with the robust FastAPI framework.
Content providers, old and new, flocked towards the enhanced offering, finding themselves captivated by the easy integration courtesy of the auto-generated documentation. It was a sweeping change that altered landscapes and created ripples of success.
But with success came new challenges, as Devon and Harper began to realize. The days began to follow a familiar pattern — a lull of activity during the weekdays, followed by the storm of server load on Fridays and the rest of the weekend.
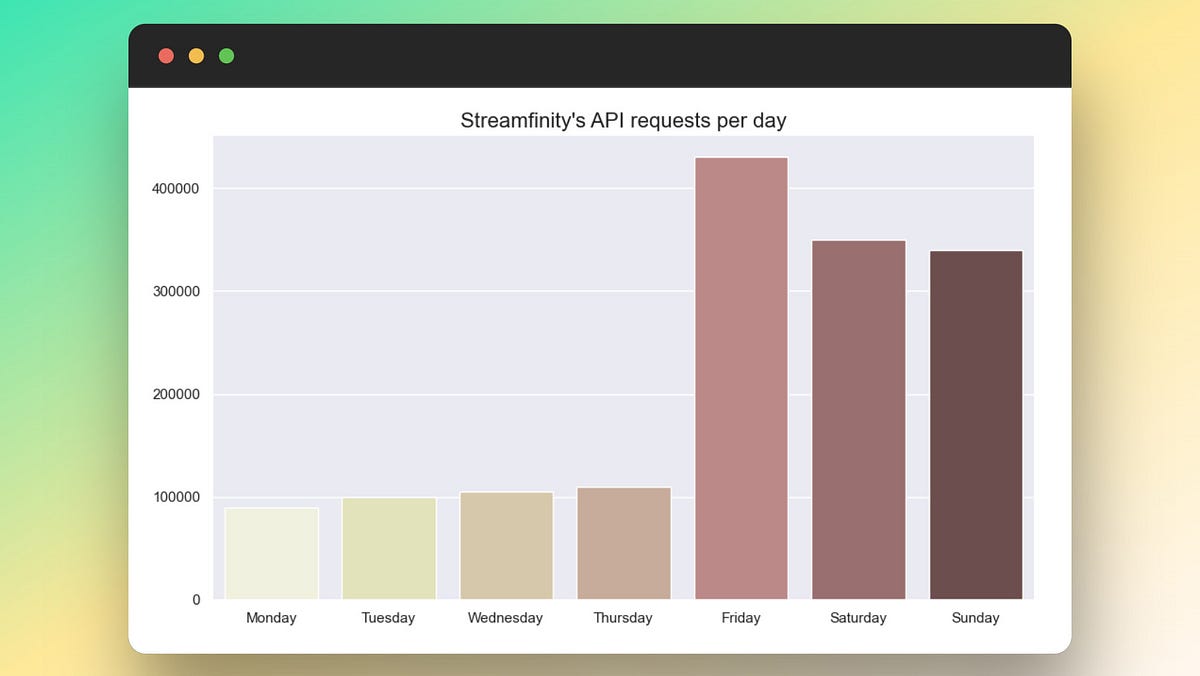
This was the day content providers typically released their new movies, creating a surge of requests starting to bear down heavily on Streamfinity’s backend servers.
The undercurrent of anticipation each week was palpable in the tech department. The once steady rhythm of keystrokes was now punctuated by anxious glances at server load monitors, especially as Friday approached.
The expansion of cloud server capacity offered only a temporary respite and was far from a sustainable solution, particularly as costs began escalating exponentially.
Further analysis uncovered that most requests originated from users browsing for movies, leading to the ‘GET movies’ endpoint being accessed 95% of the time.
On the other hand, the write requests predominantly came from new movies being added by customers and ratings assigned to film after viewing.
Since databases are typically optimized for read-intensive or write-intensive tasks, Devon suggested segregating read and write operations presented a logical and potentially more efficient solution.”
Chapter 2: The CQRS Revelation

Armed with a fresh coffee, Devon embarked on his deep dive into the captivating world of CQRS — Command and Query Responsibility Segregation.
His eyes were fixed on his glowing computer screen as he skimmed through various resources, blog posts, and digital forums.
CQRS, a term brought into prominence by Greg Young, emerged as a deviation from the conventional CRUD (Create, Read, Update, Delete) model that dominated software architecture. Young’s writings and video lectures were Devon’s initial roadmap to understanding CQRS.
CQRS pivoted on a simple yet ground-breaking principle: it suggested splitting a system’s operations into two clear-cut categories — commands (writes) and queries (reads).
This defied the traditional model where the same data structure catered to read and write operations.
In the heart of Eric Evans’ influential book, “Domain-Driven Design: Tackling Complexity in the Heart of Software”, Devon unearthed implicit references to the CQRS pattern. Although not explicitly named, the inherent concept became a critical validation for this innovative approach.
The profound implication of this separation was evident: by treating reads and writes independently; one could fine-tune each operation based on its unique requirements.
This opened up significant optimization possibilities for their high-read ‘GET movies’ endpoint.
While delving further into CQRS, Devon discovered its strong ties with the Event Sourcing architectural pattern, where state alterations were recorded as an event sequence. This revelation further broadened the prospects for system resilience and state reconstruction.
Devon’s excitement heightened as the potential of CQRS unraveled. The concept was straightforward, the segregation was elegant, and the application promised efficiency.
However, he also understood the added complexity this could introduce. Splitting operations might require doubling the work, ensuring consistency could become challenging, and team members must learn and adapt to this new model.
But for the promising horizon, it revealed, the trade-off seemed worth the effort.
As the dawn crept in, ushering in a new day, Devon felt a sense of enlightenment. He acknowledged the pioneers, Young and Evans, who dared to reevaluate software architecture norms, paving the path for a scalable, efficient future.
With CQRS, he envisaged a journey of innovation marked with challenges, learnings, and triumphs.
Chapter 3: The Green Light

As the early morning sun washed over the conference room, Devon stood poised, the product of countless hours of research in his hands — a revolutionary proposal — the adoption of CQRS.
Across the table was Harper, their CTO. Known for her strategic insight and unerring vision, Harper’s approval was the gateway to implementing Devon’s idea.
Devon launched into his presentation, outlining their escalating server costs and swelling user requests. He then unfolded the principle of Command and Query Responsibility Segregation (CQRS), crafting a compelling narrative of a system where read and write operations were optimized individually.
His presentation concluded with a medley of reactions — intrigue, skepticism, curiosity. Questions flew across the room, reflecting the team’s engagement with the novel proposition.
Amid the discussions, one team member brought up event sourcing, often linked with CQRS, as it offered an additional layer of power. However, the inclusion of event sourcing would complicate the implementation process.
Devon acknowledged this, saying, “Event sourcing has its merits but represents a radical shift in our data handling. Before we tackle that, let’s focus on segregating our read and write operations first.”
Throughout the exchange, Harper had been silently absorbing the arguments.
Finally, she voiced her thoughts. She commended the team’s lively engagement and Devon’s well-thought-out proposition. The complexities were evident, but so was the potential for enhanced performance and cost efficiency.
“Devon’s approach is measured and prudent,” Harper began, her tone steady, authoritative, “Before we dive into the full implementation, I suggest we create a prototype first. A prototype demonstrating the benefits of CQRS for our high-read operations like ‘GET movies’. Only after this success should we consider diving deeper.”
A sense of relief swept the room as Harper gave her approval. The green light was on; the prototype for the CQRS project was about to commence.
With roles assigned — from rewriting code to segregating databases to testing — the team dispersed, each member ready to play their part in this venture.
Chapter 5: The Materialized View Magic

As the team journeyed further into implementing CQRS, they confronted the challenge of optimizing the ‘GET movies’ endpoint — a performance bottleneck due to the involved join operation between the ‘movies’ and ‘actors’ tables. Numerous solutions were explored, each with its trade-offs.
One plausible approach was creating a new table that consolidated the ‘movies’ and ‘actors’ data. Whenever a movie was added or modified, corresponding updates would be carried out in the new table. This synchronization could be achieved through database triggers or additional business logic.
However, maintaining this secondary table would undoubtedly increase the system’s complexity, thereby becoming a potential source of future issues.
Searching for a more elegant solution, the team turned to a feature native to their MS SQL Server environment — indexed views, also known as materialized views.
These views store the result of a query like a standard view and persist data like a table, significantly accelerating read operations.
Leveraging the power of indexed views, they could pre-calculate the join operation between the ‘movies’ and ‘actors’ tables and retain the results.
This allowed each ‘GET movies’ request to circumvent the resource-intensive join operation and instead fetch the pre-computed results directly from the materialized view.
Crucially, this approach didn’t require additional triggers or modifications on the ‘movies’ or ‘actors’ tables, thereby preserving the system’s simplicity. Designed for automatic self-updating, the view stayed up-to-date whenever a record was added or altered.
To refresh our understanding, remember that a movie involves multiple actors; conversely, an actor can feature in multiple films. We represent this relationship in our model as follows.
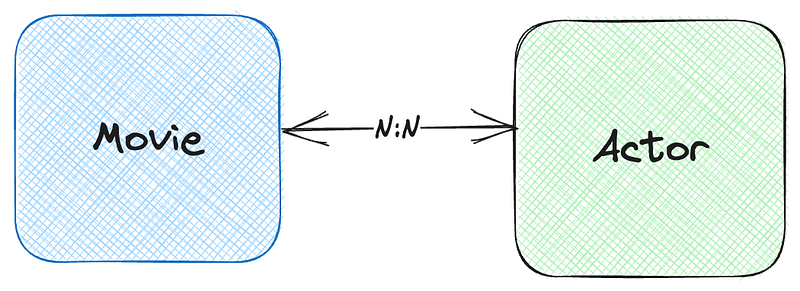
Recalling our previous article, we implemented this relationship in our database using SQLModel. We defined an additional class, MovieActorLink, to represent the many-to-many relationship between movies and actors. Here's how we set it up:
class MovieActorLink(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
movie_id: int = Field(foreign_key="movie.id", default=None)
actor_id: int = Field(foreign_key="actor.id", default=None)In our database, it is represented as follows.

We designed a materialized query to retrieve both movies and their corresponding actors directly. This query unifies the Movie and Actor tables by utilizing the MovieActorLink table. The SQL command for creating the view appears as follows.
CREATE VIEW vMovieWithActors
WITH SCHEMABINDING
AS
SELECT m.id as movie_id,
m.title,
m.length,
m.synopsis,
m.release_date,
m.director,
m.genre,
m.rating,
a.id as actor_id,
a.name,
a.date_of_birth,
a.character,
a.gender
FROM dbo.Movie m
JOIN dbo.MovieActorLink mal ON m.id = mal.movie_id
JOIN dbo.Actor a ON a.id = mal.actor_idAdding a unique clustered index is mandatory beyond creating the view itself. In our case, we generate this using the movie_id and actor_id fields.
CREATE UNIQUE CLUSTERED INDEX IDX_MovieWithActors ON
vMovieWithActors (movie_id, actor_id)Once this view is created, we can connect it to our FastAPI endpoint.
Chapter 6. Using the view from FastAPI

With the indexed view in place, the next step was integrating it with a FastAPI endpoint for retrieval. The development team’s initial approach was to create a new class, extending SQLModel, which referenced the view using the table argument.
However, they encountered a significant obstacle: SQLModel didn’t natively support SQL views. Their attempts were met with a barrage of errors, indicating that a straightforward implementation was off the table.
class MovieWithActors(SQLModel, table="vMovieWithActors"):
movie_id: int
title: str
length: int
synopsis: str
release_date: str
director: str
genre: str
rating: float
actor_id: int
name: str
date_of_birth: str
character: str
gender: intSo, the team took a different approach. They tried crafting the query themselves and appending the necessary parameters directly to it. The resulting endpoint definition, while not perfect, worked effectively by utilizing the materialized view.
@router.get("/")
def get_movies_with_actors(
params: PaginationParams = Depends(),
session: Session = Depends(get_session)
) -> List[MovieWithActors]:
with session.begin():
query = (f"SELECT * FROM vMovieWithActors ORDER BY movie_id OFFSET {params.skip}"
f" ROWS FETCH NEXT {params.limit} ROWS ONLY")
result = session.execute(text(query))
movies = [MovieWithActors(**dict(row)) for row in result.fetchall()]
return moviesThe function get_movies_with_actors is defined as a FastAPI endpoint that retrieves movies with their corresponding actors from the database.
It takes two parameters:
params: An instance ofPaginationParamsclass, which encapsulates parameters for pagination (like the number of records to skip and the maximum number of records to fetch). TheDepends()function indicates that FastAPI will inject the parameters based on the HTTP request parameters. UsingPaginationParamsalso ensures that only numerical values are inserted into the query, thus protecting against SQL injection attacks by limiting the range of acceptable input.session: A database session is needed to execute the SQL queries. This is also injected by FastAPI, using theget_sessiondependency function.
Within the function:
- A context manager (
with session.begin():) is used to start a transactional block. Any operations executed within this block are part of the same database transaction. - An SQL query is constructed as a string. This query is designed to select all records from the
vMovieWithActorsview, order them by themovie_id, and apply pagination based on theparamsinput. - The query is then executed against the database using the
session.execute(text(query))statement, wheretextis a SQL Alchemy function used to represent literal SQL text that can be directly executed. - The query results are fetched and converted into instances of the
MovieWithActorsclass. This is done by iterating over the rows of the result, converting each row into a dictionary (dict(row)), and using that dictionary to instantiateMovieWithActorsobjects (MovieWithActors(**dict(row))). - Finally, a list of
MovieWithActorsinstances is returned from the function, which FastAPI automatically converts into a JSON response.
Chapter 7: The prototype demo

The air was filled with excitement as dawn broke over Streamfinity’s offices. The day of the prototype demo had finally arrived. Devon, the guiding force behind the project, gathered his team in their high-tech presentation room.
Their task was to demonstrate the working of their new materialized view and the tremendous performance improvements it brought to the system.
The audience was a mixture of stakeholders, from developers and testers to product managers and senior executives. Most importantly, their CTO, Harper, was also in attendance, her keen eyes watching their every move.
Devon initiated the demo by revisiting the ‘GET movies’ endpoint. He shared how this endpoint had once been a performance bottleneck, attempting to handle requests that required a join operation between the ‘movies’ and ‘actors’ tables.
The team overcame this issue by utilizing a materialized view, effectively pre-computing the join operation and storing the results for quicker access.
With a few clicks, Devon navigated to the newly optimized endpoint, running a few commands to reveal its lightning-fast response times. The room erupted into impressed murmurs as they compared it to the old system. The improvement was not only apparent but also substantial.
Despite the success, Devon didn’t shy away from discussing their challenges. He elaborated on the team’s journey, explaining how SQLModel, the tool they initially hoped to use, did not directly support SQL views, leading to error messages and dead ends.
Devon further explained how they had to revert to manually creating the SQL query and adding the required parameters. Though the resulting endpoint definition wasn’t as polished as it would have liked, it worked effectively, making optimal use of the materialized view.
However, Devon reassured the room the team was already investigating ways to improve this. They explored methods to integrate SQL views with SQLModel or other alternatives that might offer cleaner, more elegant solutions.
As the demo concluded, the room filled with applause. Devon and his team had shown their innovation and technical prowess, ability to tackle obstacles head-on, and unwavering commitment to improving their system.
It was clear from the demo that Streamfinity was on the verge of significant evolution. Despite its challenges, this new approach signaled a step towards greater efficiency and performance. The prototype demo day marked an essential milestone in their journey, but as Devon reminded everyone, the adventure was far from over.
Chapter 8: The Road Ahead

As the last echoes of applause from the demo day faded away, the Streamfinity team stood at the threshold of a new era. The project had brought a whirlwind of change, innovation, and growth — not only in their system but also in their approach and perspective.
Devon, Harper, and the rest of the team took a moment to reflect on their journey. They had traversed a path with technical challenges, from escalating server costs to the performance bottleneck of the ‘GET movies’ endpoint.
They had wrestled with the complexities of database management, grappling with the intricacies of SQLModel and SQL views.
Each obstacle they encountered had been an opportunity to learn, innovate, and grow.
They embraced the principle of Command and Query Responsibility Segregation (CQRS), charting new territories in their quest for an efficient, scalable solution.
Also, they delved deep into the magic of materialized views, using this powerful tool to dramatically transform their API's performance.
However, the project was far from complete. The prototype demonstration marked a significant milestone, but a road was still stretching ahead, with potential and opportunities for further enhancement.
They had identified areas of improvement — a more elegant integration of SQL views with SQLModel, a better error handling system, and the exploration of event sourcing.
Feel free to explore our prototype in this GitHub repository, where you’ll find instructions in the README file. These instructions will guide you through installation and help you get the system up and running.
Happy coding!



