How Did AlphaGo Beat Lee Sedol?
From AlphaGo to Tic-Tac-Toe: Building Your First AI Game Player

Watching AlphaGo face Lee Sedol in 2016 was unforgettable. There was an AI program taking on one of the greatest Go players in history — and winning. If you haven’t seen AlphaGo — The Movie yet, stop reading and watch it. Seriously. I’ll wait.
The documentary captures something extraordinary: not just the DeepMind team’s breakthrough but also Lee Sedol’s incredible grace in what must have been one of his most challenging moments.
After watching those matches, I couldn’t help but wonder: How exactly does a computer learn to play a game? While Go is immensely complex, the principles behind game-playing AI can be explored with simpler games, like Tic-Tac-Toe.
In this article, we’ll build a simple AI using those same principles. No, we won’t be creating the next Go champion, but you’ll grasp the same fundamental principles that eventually can be scaled up to beat a world champion.
Using modern tools like Gymnasium, we will create an AI that learns through the same basic process — by playing against itself and learning from experience.
Don’t worry if you’re new to AI — if you know some Python basics, you’re ready for this journey. I’ve put all the code in this GitHub repository so you can follow along or experiment on your own.
My path into reinforcement learning
After 30 years of programming and a few years of working with deep learning and TensorFlow, reinforcement learning remained my blind spot. But I kept seeing these incredible examples of AIs mastering Atari games — playing Breakout better than any human, discovering strategies no one had thought of. That caught my attention.
AI was doing something beyond pattern matching — learning to play through pure trial and error, just like we do.
That curiosity led me down several learning paths. I started with Hugging Face’s reinforcement learning course by Thomas Simonini. The course allows you to recreate classic Atari experiments with reinforcement learning like Space Invaders and Breakout.
There was something fascinating about watching my agents grow from random button-mashing to skilled gameplay. The course’s global leaderboard added a competitive spark that kept me returning.

To deepen my understanding, I explored several other outstanding resources:
- David Silver’s reinforcement learning lectures, offering insights from a key member of the AlphaGo team
- UC Berkeley’s CS 285 course on Deep Reinforcement Learning (Fall 2023), providing a comprehensive theoretical foundation
- Stanford’s CS234 Reinforcement Learning course (Winter 2023), offering another valuable academic perspective
- Nicholas Renotte’s practical tutorials on implementing reinforcement learning in games
Having some deep learning background helped, but reinforcement learning introduced this extra dimension of agents actively exploring and learning from their environment. It was like adding a strategic gaming layer to everything I knew about AI.
This curiosity led me to the Tic-Tac-Toe project. After exploring various approaches, I chose Q-learning because it strikes a perfect balance — simple enough to understand completely but powerful enough to teach an AI real strategy.
Building our AI player
While AlphaGo mastered the complex game of Go using deep neural networks and advanced algorithms, we will start with something more manageable: Tic-Tac-Toe. Don’t let its simplicity fool you — this game is perfect for learning core AI concepts because it:
- Has clear rules and limited moves
- Provides quick feedback with short games
- Requires both tactical moves and strategic thinking
- Demonstrates key concepts like state evaluation and decision-making
Our project breaks down into three essential parts:
- Creating a game environment where our AI can play
- Teaching the AI through Q-learning
- Training through self-play
Think of it as teaching a child to play Tic-Tac-Toe. First, you create the playing space and explain the rules (our environment). Then, you help the child understand good and bad moves (Q-learning). Finally, they improve by practicing with others (self-play).
We will build this using Gymnasium, the framework that powers more complex AI training environments. While our game is simpler than Go, the fundamental principles of learning, decision-making, and improvement remain the same.
The journey begins with Q-learning, the algorithm powering our solution.
Understanding Q-Learning
Q-learning might seem overwhelming at first. But here’s the thing — it’s pretty straightforward when you break it down. Following a simple learning cycle, let’s visualize how Q-learning functions in our Tic-Tac-Toe game.

- Observes the current game state
- Decide between exploring new moves or exploiting known good moves
- Receives a reward (e.g., -1 for loss, +1 for win, 0 for draw)
- Updates its knowledge (Q-values) for that state-action pair
- Moves to the new game state
But how does it start learning? Like a beginner, it starts by making random moves. This exploration phase is essential for the AI to try various moves and learn from the outcomes.
Each game ends with a reward: positive for winning, negative for losing, and zero for a draw. Over time, these rewards are linked to the moves that led to them.
In Q-learning, each action is assigned a ‘quality’ score, or Q-value. The Bellman equation helps update this score for better decision-making. Higher scores mean better moves.
For instance, the AI might learn that taking the center square early leads to better outcomes, giving that action a high Q-value.
At the heart of Q-learning is the Bellman equation:
Q(s, a) = Q(s, a) + α[R + γ * max Q(s’, a’) — Q(s, a)]
This equation updates the Q-value for a given state-action pair (s, a). Here:
- Q (s, a) is the current Q-value for state sss and action aaa,
- α is the learning rate, controlling how much new information overrides old,
- R is the immediate reward received,
- γ is the discount factor, weighing future rewards,
- max a′ Q (s′,a′) represents the maximum expected future reward for the next state s′.
The Bellman equation’s idea is simple but powerful: the quality of a move considers its immediate reward and the future rewards it leads to. In chess, a move’s value is more than its immediate outcome; it also concerns the winning positions it establishes later.
Q-learning is ideal for tabular data — situations where we can list all possible states and actions in a table. Tic-Tac-Toe, with its limited board positions and moves, is perfect for this. But complex games like Go need more sophisticated approaches, like AlphaGo’s deep learning model.
The real power of Q-learning comes from self-play. Our AI builds a strategy guide by playing thousands of games against itself. It learns from successes and failures, becoming a stronger player over time.
As it gains experience, it relies less on random moves and more on learned strategies — just like a human player. While Q-learning has many nuances, this foundational understanding helps us follow its progress as we build our game.
Let’s set up our Tic-Tac-Toe environment and see these concepts in action.
Setting up our game environment
To learn, the AI needs an environment to play in. Think of it as a video game. The AI needs to see the game state, make moves, and receive feedback on its performance.
Enter Gymnasium, a standard toolkit for reinforcement learning created by OpenAI. The main goal of Gym is to provide a rich collection of environments for RL using a unified interface. It powers everything from simple arcade games to complex simulations. Whether you’re teaching an AI to play Space Invaders, land a rocket, or drive a car, Gymnasium provides a consistent way to:
- Show the AI the game state.
- Allow it to make moves.
- Provide feedback through rewards.
- Update the game state.
We will create our own Tic-Tac-Toe environment using Gymnasium’s framework. Here’s the core of our game environment:
class TicTacToeEnv(gym.Env):
metadata = {"render_modes": ["human", "rgb_array"], "render_fps": 30}
def __init__(self, render_mode: Literal["human", "rgb_array"] = "human"):
super().__init__()
self.renderer = PygameRenderer()
self.render_mode = render_mode
self.observation_space = spaces.Dict({
"board": spaces.Text(min_length=9, max_length=9, charset="XO-"),
"current_player": spaces.Discrete(2)})
self.action_space = spaces.Discrete(9)
self.state = self._create_initial_state()
def reset(self, seed: Optional[int] = None, options: Optional[Dict] = None) -> Tuple[Dict[str, Any], Dict]:
super().reset(seed=seed)
self.state = self._create_initial_state()
self.state.current_player = random.choice([Player.X_SYMBOL, Player.O_SYMBOL])
return self._get_observation(), {}
def step(self, action: int) -> Tuple[Dict[str, Any], float, bool, bool, Dict]:
if self._is_valid_move(action):
self._make_move(action)
reward, self.state.done = self._evaluate_game_state()
if not self.state.done:
self._switch_player()
return self._get_observation(), reward, self.state.done, False, {}
return self._get_observation(), -1, True, False, {}This code creates a game environment where:
- The AI sees the board as a string of X’s, O’s, and dashes
- It can make moves by choosing a number 0–8 (representing board positions)
- It gets rewards for winning moves and penalties for invalid ones
- The game tracks whose turn it is and when the game ends
Each method serves a specific purpose:
__init__: Sets up the game rules and what the AI can see and doreset: Starts a new game with a clean boardstep: Handles one move and returns the results
Later, we will see how our Q-learning agent uses this environment to learn optimal play.
Teaching Ai to play Tic-Tac-Toe
Now that we have our game environment, let’s build the brain of our AI player. Our QLearningAgent class implements the concepts we discussed earlier - learning from experience, balancing exploration with known good moves, and updating its strategy based on rewards.
@dataclass
class AgentConfig:
learning_rate: float = 0.1 # How quickly the AI learns from new experiences
discount_factor: float = 0.95 # How much future rewards matter vs immediate ones
exploration_rate: float = 1.0 # Starting chance of trying random moves
exploration_decay: float = 0.9995 # How quickly to reduce random exploration
min_exploration_rate: float = 0.01 # Always keep some randomness
initial_q_value: float = 0.01 # Starting value for new movesThe heart of our AI is the QLearningAgent class. It keeps track of what it has learned in a Q-table - essentially a big lookup table that stores how good each move is in each board position:
class QLearningAgent:
def __init__(self, action_space: Discrete, config: Optional[AgentConfig] = None):
self.action_space_size = action_space.n
self.config = config or AgentConfig()
self.q_table: Dict[str, Tuple[float, ...]] = {}
self.exploration_rate = self.config.exploration_rateWhen it’s the AI’s turn to move, it follows these steps:
- Look at the current board (
choose_actionmethod):
def choose_action(self, state: str) -> int:
available_moves = self.find_available_moves(state)
# Sometimes make a random move (exploration)
if random.uniform(0, 1) < self.exploration_rate:
return random.choice(available_moves)
# Otherwise choose the best known move
return self.select_best_move(state, available_moves)2. After each move, update what it learned (update method):
def update(self, state: str, action: int, reward: float, next_state: str, done: bool):
current_value = self.q_table[state][action]
# Calculate the value of this move based on reward and future possibilities
if done:
target_value = reward
else:
available_moves = self.find_available_moves(next_state)
future_values = [self.q_table[next_state][move] for move in available_moves]
max_future_value = max(future_values) if future_values else 0
target_value = reward + self.config.discount_factor * max_future_value
# Update our knowledge slightly toward the target value
updated_value = current_value + self.config.learning_rate * (target_value - current_value)Over time, the AI:
- It starts by trying lots of random moves to explore
- Gradually, it focuses more on moves it has found to work well.
- Updates its Q-table after every move based on the rewards it gets
- Considers both immediate rewards and future possibilities
This balance of exploration and exploitation lets our AI discover effective strategies while still being able to adapt to different opponents.
From novice to expert: The training process
Training an AI through self-play offers two approaches. We will try both:
- Training against a random player (like learning against a beginner)
- Two AIs training against each other (like two students practicing together)

Training against a random player
Let’s start with the basics: training our AI against a random player. This approach helps our agent learn fundamental strategies without being overwhelmed by complex counter-play.
Here’s how we track the learning process:
@dataclass
class TrainingConfig:
episodes: int = 1_000_000 # Total games to play
render_interval: int = 100_000 # Show game visually every N episodes
stats_interval: int = 1_000 # Print stats every N episodes
window_size: int = 1_000 # Track recent performance over N games
class TrainingStats:
def __init__(self, window_size: int):
self.recent_results: List[str] = [] # Track recent game outcomes
self.wins_x = 0 # Total X wins
self.wins_o = 0 # Total O wins
self.draws = 0 # Total draws
def get_stats(self, episode: int) -> Tuple[float, float]:
# Calculate both overall and recent performance
recent_x_wins = self.recent_results.count("X")
total_episodes = episode + 1
overall_winrate = (self.wins_x / total_episodes) * 100
recent_winrate = (recent_x_wins / len(self.recent_results)) * 100
return overall_winrate, recent_winrateThe training loop alternates between our learning agent (X) and random moves (O):
def run_episode(self, episode: int) -> None:
obs, _ = self.env.reset()
state = obs["board"]
current_player = obs["current_player"]
while not done:
# X's turn (Learning Agent)
if current_player == "X":
action = self.agent.choose_action(state)
next_state, reward, done, _ = self.env.step(action)
self.agent.update(state, action, reward, next_state, done)
# O's turn (Random Player)
else:
action = self.select_random_move(state)
next_state, reward, done, _ = self.env.step(action)
current_player = obs_next["current_player"]
state = next_stateEvery thousand games, we get a progress report:
Episode 1000
Overall - X W: 623, O W: 298, Dr: 79
Overall Win Rate: 62.3%
Recent Win (last 1000): 62.3%
Recent - X W: 623, O W: 298, Dr: 79
X Exploration Rate: 0.606This tells us:
- How often does our AI win overall
- Recent performance (last 1000 games)
- Current exploration rate (how often it tries random moves)
Two Ais training against each other
While training against random moves teaches basic strategy, the real challenge comes from playing against an equal opponent. Let’s see how we can train two AIs that learn from each other, similar to two students practicing together.
First, we set up two learning agents with identical starting conditions:
def main():
env = TicTacToeEnv(render_mode="human")
# Configuration shared by both agents
agent_config = AgentConfig(
learning_rate=0.1, # How quickly agents learn
discount_factor=0.99, # Weight of future rewards
exploration_rate=1.0, # Start fully exploratory
exploration_decay=0.999995, # Very slow decay for thorough learning
initial_q_value=0.0 # Initial move valuations
)
# Create two separate learning agents
agent_x = QLearningAgent(env.action_space, agent_config)
agent_o = QLearningAgent(env.action_space, agent_config)
training_config = TrainingConfig()
trainer = DualAgentTrainer(env, agent_x, agent_o, training_config)To track their progress, like with the random opponent we will monitor wins, losses, and draws:
@dataclass
class TrainingConfig:
episodes: int = 500_000 # Total training games
render_interval: int = 100_000 # Show visual game every N episodes
stats_interval: int = 1_000 # Print progress every N episodes
render_delay: float = 0.5 # Delay between moves (for visualization)
class TrainingStats:
def __init__(self):
self.wins_x = 0
self.wins_o = 0
self.draws = 0
def print_progress(self, episode: int, agent_x: QLearningAgent, agent_o: QLearningAgent):
print(f"\nEpisode {episode}")
print(f"Agent X Wins: {self.wins_x}, Agent O Wins: {self.wins_o}, Draws: {self.draws}")
print(f"X Exploration Rate: {agent_x.exploration_rate:.3f}")
print(f"O Exploration Rate: {agent_o.exploration_rate:.3f}")The key to self-play learning is how agents learn from each game. When one agent wins, both agents update their strategies:
def update_agents(self, current_player: str, last_moves: Dict[str, GameState],
state: str, action: int, reward: float, next_state: str, done: bool):
current_agent = self.agents[current_player]
other_player = "O" if current_player == "X" else "X"
other_agent = self.agents[other_player]
# Current player learns from their move
current_agent.update(state, action, reward, next_state, done)
# If game ends with a winner, other player learns from their loss
if done and reward != 0:
other_last_move = last_moves[other_player]
if other_last_move.action is not None:
other_agent.update(
other_last_move.board,
other_last_move.action,
-reward, # Opposite reward for the losing player
next_state,
done
)During training, we see several stages of development:
- Early Games (Episodes 1–1000):
Episode 1000
Agent X Wins: 358, Agent O Wins: 341, Draws: 301
X Exploration Rate: 0.607
O Exploration Rate: 0.607- Both agents make many random moves.
- Wins are pretty evenly distributed.
- Few strategic patterns emerge
2. Middle Stage (Episodes ~50,000):
Episode 50000
Agent X Wins: 16920, Agent O Wins: 16881, Draws: 16199
X Exploration Rate: 0.082
O Exploration Rate: 0.082- Agents start showing strategic behavior
- More games end in draws
- Less random exploration
3. Late Stage (Episodes ~100,000):
Episode 100000
Agent X Wins: 33841, Agent O Wins: 33762, Draws: 32397
X Exploration Rate: 0.018
O Exploration Rate: 0.018- Very strategic play
- A high percentage of draws
- Primarily using learned strategies.
Key observations from self-play training:
- Win rates stay close to 50–50 as both agents improve together.
- Draws become more common as agents learn optimal play
- Exploration rates gradually decrease as agents build confidence.
- Games get longer as agents make fewer mistakes.
This dual-learning approach produces stronger players than training against random moves because:
- Both agents continuously adapt to counter each other.
- They learn from both winning and losing positions.
- The challenge level increases as both improve
- They discover and counter advanced strategies.
It’s fascinating to watch two AI agents start from complete randomness and gradually develop sophisticated strategies through self-play — much like how human players improve by practicing against worthy opponents.
How well does it play?
Training stats reveal the agent’s progress, reaching a win rate of around 75–80% against a random player. However, to understand how well our agent learned to play Tic-Tac-Toe, we must evaluate its performance in both scenarios.
Against a random player
First, let’s examine the results against a random player. How did the agent achieve this level of performance? The training graphs reveal several patterns.
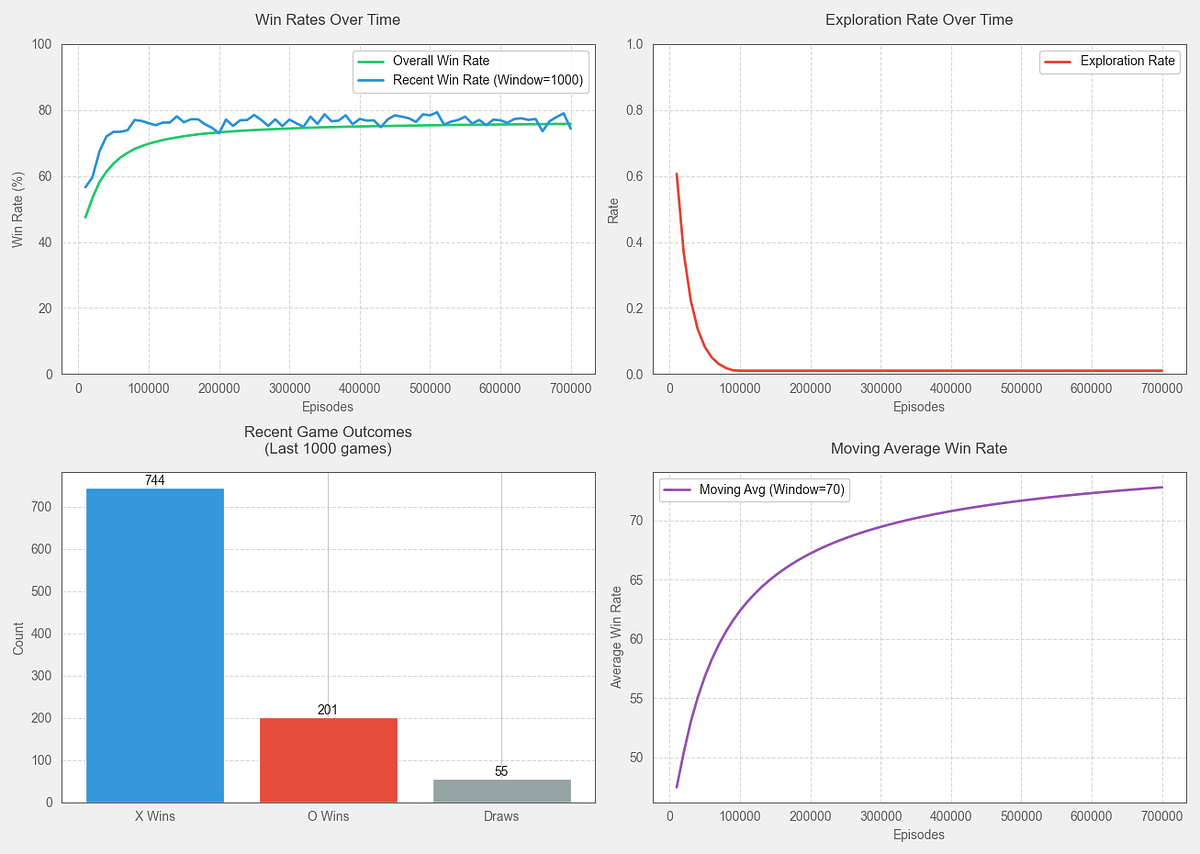
- Rapid Initial Learning: The agent’s win rate climbed sharply in the first 100,000 episodes, starting from around 45% and quickly reaching about 65%. This shows how quickly it learned basic winning strategies.
- Steady Improvement: The win rate gradually improved after the initial surge, stabilizing around 75–80%. This pattern is typical in reinforcement learning — quick early gains followed by slower, incremental improvements.
- Exploration vs Exploitation: The exploration rate graph shows how the agent transitioned from mostly exploring (trying random moves) to exploiting its learned strategies. This balance was crucial for developing robust gameplay.
Against Another AI Agent
We see a different pattern when we pit two trained agents against each other.

The self-play results reveal sophisticated learning dynamics:
- Perfect Balance: Both agents achieve remarkably similar win rates (~35%), with X winning 286,609 games and O winning 289,341 games out of nearly 900,000 played. This near-perfect balance shows that neither player has found an exploitable advantage.
- Rising Draw Rate: Perhaps most interesting is the steady increase in draws from ~15% to ~35% as training progresses. This mirrors what we see in human expert play — more games end in draws as players get better.
- Strategic Depth: The high number of draws (298,051) suggests both agents have learned optimal defensive strategies. Like human experts, they’ve learned that perfect play often leads to a draw in Tic-Tac-Toe.
- Exploration Strategy: Both agents show identical exploration patterns, starting with random moves and gradually transitioning to strategic play. This shared learning journey helps explain their evenly matched performance.
This dual evaluation shows that our agent has not just learned to beat random opponents—it’s discovered the fundamental strategic principles of Tic-Tac-Toe. Against a random player, it exploits weaknesses to win consistently. It plays cautiously against an equally skilled opponent and often forces a draw, much like human experts.
Setup and Installation
Requirements:
- Python 3.12
- Poetry package manager
- Standard CPU (no GPU needed)
- Clone the repository:
git clone
https://github.com/PatrickKalkman/TicTacToe-RL-QTables.git2. Set up the environment:
poetry install
poetry shell3. Run the training scripts:
cd src
python train_agent_vs_random.py # Train against a random opponent
python train_agent_vs_agent.py # Train against selfFrom Tic-Tac-Toe to Go: Scaling AI in Complexity
Our journey from Tic-Tac-Toe to AlphaGo demonstrates the need for varied approaches in different games. While Tic-Tac-Toe has just 5,478 possible valid board positions, Go is entirely different in complexity.
A 19x19 Go board has approximately 2.1 × 10¹⁷⁰ possible positions — more than the atoms in the observable universe. This vast number of possibilities makes a Q-learning table impractical for Go, as storing every possible board position in memory is impossible.
Advanced AI systems like AlphaGo use techniques beyond simple Q-learning to tackle such complexity. For example:
- Search Algorithms: AlphaGo uses Monte Carlo Tree Search (MCTS) to evaluate possible moves efficiently.
- Pattern Recognition: Deep neural networks recognize board patterns, predicting favorable moves.
- Policy Networks and Value Networks: Policy networks guide moves, and value networks assess board positions early.
Even in our Tic-Tac-Toe project, tuning hyperparameters like learning rate, exploration rate decay, and discount factor was essential. For complex games, tuning these becomes even more critical, as AlphaGo’s neural networks involve millions of parameters that must be carefully adjusted.
What’s Next?
If you’re ready to build on this foundation, here are a few paths to deepen your understanding:
- Try minimax with alpha-beta pruning for Tic-Tac-Toe: Minimax, combined with alpha-beta pruning, makes AI move evaluations more efficient by eliminating unnecessary calculations. It’s a great next step for understanding decision-making in simpler games.
- Explore deep Q-learning for more complex games: Moving from tabular to deep Q-learning introduces neural networks to handle larger state spaces, paving the way for tackling games with higher complexity.
- Create AI for intermediate games like Connect Four or Othello: These games introduce more complexity than Tic-Tac-Toe but remain manageable, providing a balanced challenge and further developing your skills.
The journey from Tic-Tac-Toe to Go demonstrates how AI methods scale with problem complexity. Our Q-learning approach serves as a stepping stone, helping us appreciate advanced systems like AlphaGo and the breakthroughs behind them.
This is just the beginning — Stay tuned for more insights as I dive deeper into the Hugging Face course. Let’s keep exploring and learning together.



