Harnessing Local Language Models — A Guide to Transitioning From OpenAI to On-Premise Power
Keeping sensitive content secure by making the transition from OpenAI

If you’ve been following the story of Sarah and Mustafa, you’ll recall their significant milestone: creating and presenting a prototype that harnesses the OpenAI API to NeonShield’s leadership.
In our last article, we showed their convincing demonstration, which captured the attention of NeonShield’s executives and left them overwhelmed.
Their pioneering approach of utilizing artificial intelligence to streamline the creation of tenders tackled Sarah’s original problem and showcased many potential applications that the leadership hadn’t even considered.
Yet, excitement wasn’t the only sentiment in the room. There was a shared concern, the elephant in the room: the prospect of entrusting NeonShield’s sensitive documents to a cloud service was met with understandable apprehension.
In our business, preserving privacy and security isn’t just a priority — it’s an absolute necessity. The leadership asked if we could improve the prototype to keep data processing and storage in-house.
Sarah and Mustafa appreciated these concerns and agreed to take on the challenge. They knew potential solutions to provide the necessary privacy, but these would require more research and development.
This article invites you to join Sarah and Mustafa as they embark on a transformation journey — moving from the OpenAI API to a more privacy-focused solution.
As they delve into alternative AI technologies, they’ll explore how these tools could maintain NeonShield’s privacy and security standards while enhancing the DocuVortex application’s capabilities.
So, join us on this exciting adventure, and witness how Sarah and Mustafa tackle the challenge of integrating privacy at the core of NeonShield’s DocuVortex.
As always, we believe in sharing our progress and lessons. We invite you to explore our project by visiting the associated GitHub repository.
Before reading this article, we recommend you check out our initial exploration in How to Build a Document-Based Q&A System Using OpenAI and Python. It provides the groundwork and fundamental understanding for this story.
Architectural revisions: Addressing privacy concerns in DocuVortex
The following day, Sarah and Mustafa gathered around the meeting room table, preparing to dive into the architectural modifications necessary for DocuVortex.
Mustafa kicked off the conversation. “So, let’s take a step back and recall our current architecture,” he suggested. “Essentially, we have two systems: one for ingesting content and another for handling queries and retrieving answers.”
Let’s focus first on what we need to adjust in the ingest part.
Refining the DocuVortex ingest architecture
Mustafa explained, “In our existing Ingest architecture, a significant portion was dedicated to connecting with the OpenAI API. We utilized this API to generate embeddings for each chunk of text from the ingested PDFs, which were then stored in the Chroma Vector DB.”
He continued, “After reviewing our options, it’s clear that we’ll need to transition to a local embedding model for generating these embeddings.
There’s a particular model called ‘Instructor’ I’ve heard promising things about. It’s an instruction-finetuned text embedding model that can generate text embeddings tailored to our tasks. So, that seems like a good starting point. The updated architecture should resemble this image.”
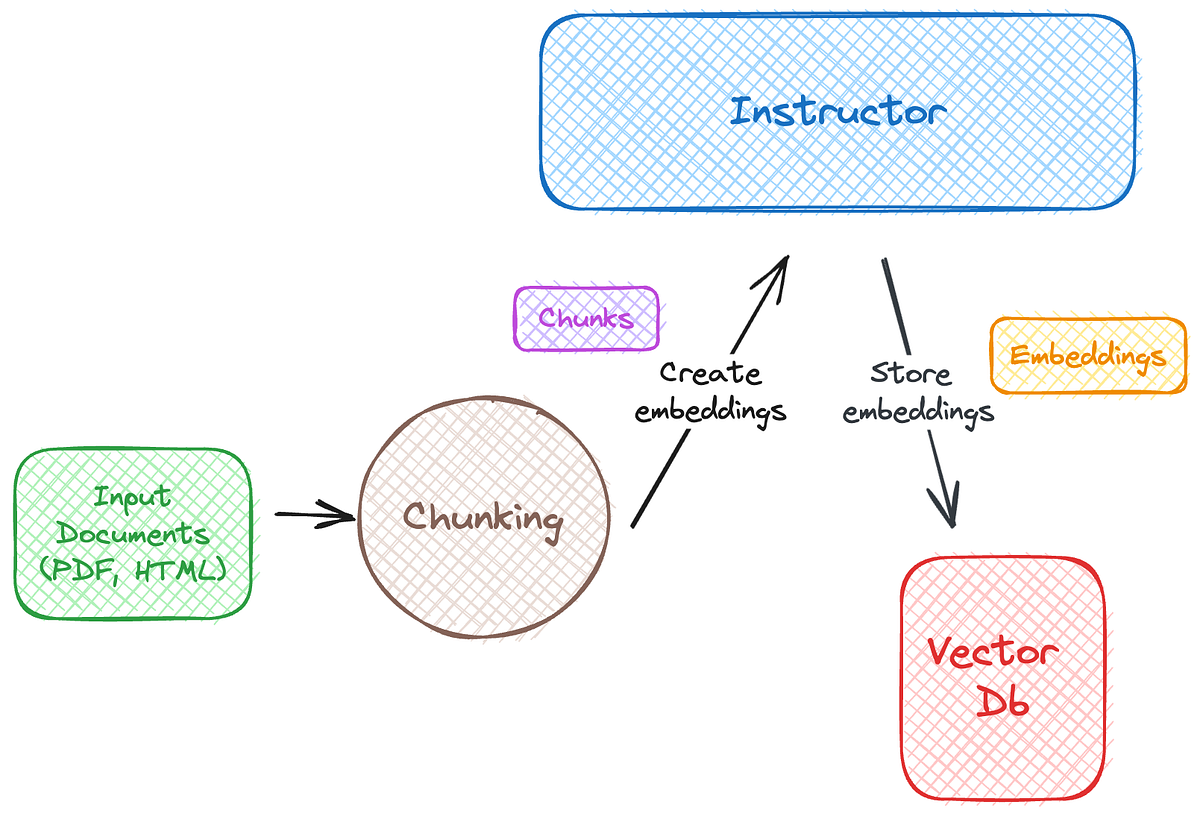
Mustafa ensured to reassure Sarah, “A lot of the process will remain unchanged, though. The PDF documents will be read, cleaned, and chunked as usual. Plus, the Chroma Vector database will continue to store the embeddings. The key adjustment lies in how we generate those embeddings.”
Sarah quickly asked Mustafa, “Do you already know what might be required in terms of infrastructure or computing power to run this Instructor model?”
Mustafa nodded in response, “I have some thoughts on that, Sarah. But, before we delve into that aspect, I’d like to shift our discussion towards the other segment of our system — the searching part.”
Refining the DocuVortex Searching Architecture
Mustafa then shifted his focus to the modifications necessary within the search part of the system.
He reminded Sarah, “The OpenAI API was instrumental in two ways within our searching process. Firstly, it was used to create embeddings of questions, which we used to identify relevant portions within our ingested documents.
Secondly, the same API was leveraged to send these pertinent text extracts and the query to the ChatGPT LLM, which would subsequently construct and deliver an answer.”
Sarah nodded in understanding, “Alright, we already have a substitute for generating the question embedding, right?”
Mustafa nodded, confirming her understanding, “Correct. We’ll use the same Instructor model to generate the question embedding.”
He continued, “We’ll start using the WizardLM model to construct the responses to our queries. It’s derived from the original LLaMA 7B model and fine-tuned for instruction-following tasks. LLaMA, or Large Language Model Meta AI, is a series of language models introduced by Meta (formerly Facebook) as part of their commitment to open science.”
Sarah inquired, “And what does the ‘7B’ signify?” Mustafa explained, “That refers to the number of tokens used to train the model. The 7B model was trained on 7 billion tokens.”
Intrigued, Sarah commented, “That seems like a substantial number. I’m increasingly keen on understanding the computation and infrastructure aspects.”
With a knowing smile, Mustafa assured her, “We’ll delve into that soon. First, let’s examine how the search architecture would look with the integration of the Instructor and WizardLM models.
Some changes will be necessary, but I believe much will remain the same.” He then showed her an image of the prospective architecture.

Mustafa reiterated, “As I’ve mentioned before, we must assess the performance of both the Instructor and the WizardLM models in ingesting and querying our content.
Clarifying expectations and infrastructure considerations

With the new plan of action in place, Mustafa wanted to set clear expectations for Sarah, particularly about the inevitable differences in output quality between their unique model and the one offered by OpenAI.
“Sarah,” Mustafa began, “it’s crucial to remember that the models we’ve been using from OpenAI and the one we’re about to embark on are quite different.
We’re transitioning from ChatGPT-3, a model trained using a staggering 176 billion parameters, to LLaMA-7B, the foundation of the WizardLM, which utilizes a significantly lower count of 7 billion parameters.”
He took a moment to let this sink in before continuing. “Now, this isn’t necessarily a drawback, but it does mean we should brace ourselves for a certain degree of quality difference in the output.”
Mustafa then moved on to the technical requirements.
“Both the Wizard and the Instructor models are rather large. The Wizard model is about 6GB, while the Instructor model comes at around 3 GB.
While running these models on a CPU is technically feasible, it’s far from ideal. The processing time for generating embeddings during ingestion or answers to queries would be excruciatingly long.
Our best bet? A GPU.”
With a hopeful look, he added, “I’ve been in touch with our pen-test department, and they’re willing to let us borrow one of their machines usually employed for penetration testing.
They use it primarily for password strength checks during their security audits. I believe it’s equipped with a V100 or A100 GPU, which will be sufficient for our initial tests.”
Sarah enthusiastically replied, “That sounds like a solid plan, Mustafa. If there’s anything I can do to expedite any process or cut through red tape, just let me know.
With the backing of the entire management, I anticipate smooth sailing ahead.”
Sarah flashed a mischievous smile. “Just one more question?” she teased. Mustafa couldn’t help but burst into laughter. “Ah, the infamous project manager’s question!
No worries, Sarah, I’ve got you covered. Give me till the end of the week. I promise you’ll have something to see!” he assured her in good humor.
Showtime: The Big Reveal
It was a Friday morning, greeted by rain pattering on the windows. The office was still empty, save for Mustafa, who arrived earlier than usual to set the stage for the big demo.
Focused and prepared, Mustafa organized all the necessary elements for the demonstration. He wanted to run through the process from scratch, so he wiped out all the previously ingested data from the vector database.
This way, Sarah could trace the entire journey from beginning to end, just like an untraveled path.
Just as Mustafa was double-checking his setup, his phone buzzed. It was Sarah, apologizing for being held up by the whims of public transport. She would be about 15 minutes late.
Mustafa couldn’t help but feel relieved; those extra few minutes were like a small gift from the universe, granting him more time to fine-tune his presentation.
Sarah entered the last raindrops of a sudden shower still dripping from her coat. She eyed Mustafa, “How are we doing?” she inquired. Mustafa let out a sigh that seemed to deflate him slightly. “Well…” he began, his voice carrying the weight of his effort, “it’s been like scaling a mountain, to put it lightly.”
Mustafa elaborated, sharing that the implementation task had proven to be more stubborn than they’d anticipated. Wrestling with infrastructure complications, such as installing and configuring the correct video drivers and CUDA toolkit, had stretched his patience to its limits. “You’ve no idea how much I appreciate the assistance from the pentest team,” he admitted, a sense of relief seeping into his words.
Installation of Requirements
Alright, let’s dive in. I want to start from the beginning so you can follow every step. I’m sure you’ll have questions,” Mustafa said.
“So, we’re still using DocuVortex, right? The updated one from our chat earlier this week?” Sarah interjected. Mustafa nodded, “Exactly. The updates went smoothly, so there were no real hiccups there. First things first, we clone the git repository on our machine, then we install all the necessary packages.”
“By packages, you mean the open-source components that DocuVortex uses, right?” Sarah asked for clarity. Mustafa affirmed, “Yes, that’s right,” as he typed pip install -r requirements.txt into the terminal, swiftly installing all packages. Sarah seemed impressed, "Wow, that's a hefty list of packages." Mustafa smiled, "Yes, but remember, this includes all dependencies for these packages."
Sarah followed along, then asked, “Does this also include the Instructor and the WizardLM model?” Mustafa shook his head, “No, those will be downloaded when needed.” Sarah’s eyebrows knitted in thought, “Every time?” Mustafa replied, “No, they’re cached once downloaded on the machine.”
Ingesting the Documents
“Alright, it’s time to focus on the document ingestion process. Keep an eye on the terminal as we set things in motion,” Mustafa prompted, fingers poised over the keys. He swiftly entered python3 ingest.py and hit enter.
Sarah watched as the system downloaded and loaded the Instructor_Transformer, but everything else appeared as before. “So, it seems like the actual parsing, cleaning, and chunking process remained the same?” she queried.
Mustafa nodded, confirming her observation, “Yes, that’s correct. We anticipated no alterations, and it turned out just as expected.”

Querying the Documents
Alright, we’re ready for the grand finale. I’ll get the search process rolling by entering python3 query.py. Watch closely. You'll see it download the necessary models before bringing up the prompt."
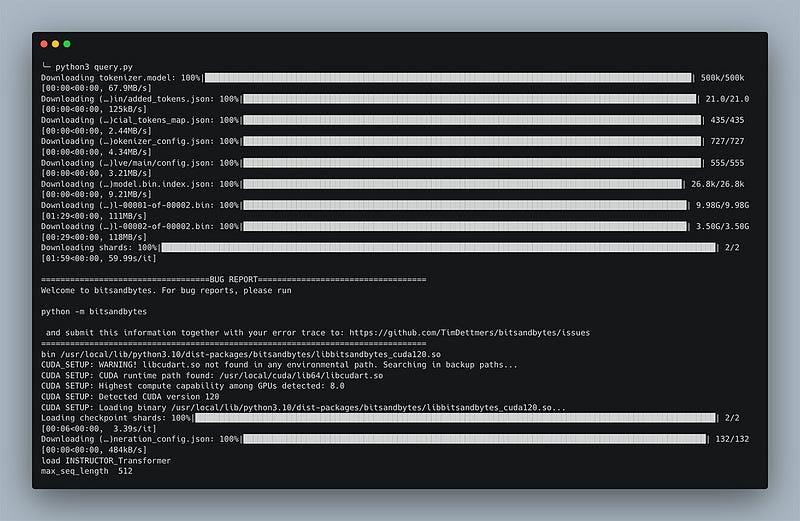
Sarah leaned in, her eyes wide. “Hold on, do I see that right? One file is 9.89GB, and the other is 3.50GB?” Mustafa nodded, “That’s correct. Those are the trained model files for WizardLM. They’ve been downloaded and are now ready for use.”
“Alright, time for the big test. I’ll input the same query we used with the OpenAI API — ‘What is the conclusion of the Cybersecurity Risk paper?’” Mustafa explained. Nearly a minute passed before the response was finally displayed on the screen.

Sarah looked surprised, “That’s impressive. The answer matches the original one.”
But does it always take this long? Mustafa nodded, “Unfortunately, yes. And remember, that’s even with the A100 GPU working at full tilt.” Sarah frowned slightly, “How do we know that we’re utilizing the GPU?”
Mustafa smiled at her keen question, “That’s an excellent point, Sarah. I’ve certainly made my share of mistakes during implementation.”
Now, I rely on an open-source tool called gpustat by Jongwook Choi. It allows us to monitor GPU usage, ensuring we’re truly harnessing its processing power.
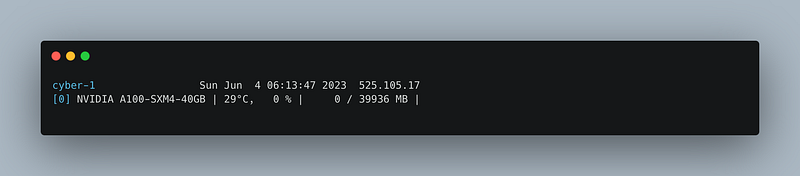
Sarah’s eyes gleamed with admiration, “Mustafa, I must say I’m truly impressed. We’re running the entire process — from ingestion and embedding creation to querying — right here, and the results are on par with what we had before.”
Mustafa nodded, a hint of caution in his tone, “Yes, though I’ve noticed during my tests that our model sometimes churns out strange or incorrect answers, unlike when we used the OpenAI API.”
Sarah smiled reassuringly, “Right, you mentioned that the output might be a bit rougher given we’re using much smaller models than the GPT-3 one with the API.
But honestly, you’ve made astounding progress. I recognize that more testing and evaluation of other models for embedding and querying is needed.
However, I’m curious about one other thing…”
Mustafa laughed, anticipating her question, “I know you’re itching for the technical implementation details.” Sarah’s grin widened, “Yes, exactly!”
DocuVortex implementation
Time to submerge ourselves in the modifications we made to the original DocuVortex implementation. We’ll kick things off by exploring the adaptations to the process of PDF document ingestion.
Ingestion
As you might recall, the true workhorse of our operation is the VortexPdfParser class. This class is entrusted with parsing the PDF documents nestled in the ‘docs’ folder; as it turns out, it didn’t need any alterations.
Where I did wield the coding hammer was in the VortexIngester class. It now uses the HuggingFaceInstructEmbeddings class and hkunlp/instructor-xl model. The parameter {“device”: “cuda”} we’ve included is a clear signal to leverage our GPU.
Beyond that, it’s pretty much business as usual. We’re sticking to our guns with Chroma.from_documents for building the embeddings. And once again, the langchain library has made all of this remarkably straightforward.
def _create_and_persist_vector_store(self, chunks: List[docstore.Document]) -> None:
"""Create and persist Chroma vector store.
Args:
chunks (List[docstore.Document]): List of document chunks.
"""
instructor_embeddings = HuggingFaceInstructEmbeddings(
model_name="hkunlp/instructor-xl",
model_kwargs={"device": "cuda"}
)
logger.info("Loaded embeddings")
vector_store = Chroma.from_documents(
chunks,
instructor_embeddings,
collection_name=COLLECTION_NAME,
persist_directory=PERSIST_DIRECTORY,
verbose=True
)
logger.info("Created Chroma vector store")
vector_store.persist()
logger.info("Persisted Chroma vector store")Let's now look at the changes regarding the query process.
Diving into the Querying Process
The modifications to our querying process primarily involved tweaks to our VortexQuery class. This class now employs the LlamaTokenizer and LlamaForCausalLM to load the pre-trained model named TheBloke/wizardLM-7B-HF.
Sarah responded, “That seems straightforward. So, if we wanted to switch to a different model, we’d need to change the model string?”
Mustafa nodded, “Exactly. However, the new model needs to be based on the same architecture as the original one. If not, we must adapt the code to use a different class.”
“I noticed you’re using RetrievalQA now instead of the ConversationalRetrievalChain. Is there a specific reason?” Sarah asked.
Mustafa replied, “Indeed, good observation. They are very similar, but the ConversationalRetrievalChain includes an additional parameter, chat_history, for handling follow-up questions.
However, I chose not to use it for this particular implementation.
def _initialize_chain(self):
"""Initialize the retrieval chain.
Returns:
RetrievalQA: A configured retrieval chain.
"""
tokenizer = LlamaTokenizer.from_pretrained("TheBloke/wizardLM-7B-HF")
model = LlamaForCausalLM.from_pretrained("TheBloke/wizardLM-7B-HF",
load_in_8bit=True,
device_map='auto',
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
generation_pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=1024,
temperature=0,
top_p=0.95,
repetition_penalty=1.15
)
local_llm = HuggingFacePipeline(pipeline=generation_pipe)
instructor_embeddings = HuggingFaceInstructEmbeddings(
model_name="hkunlp/instructor-xl",
model_kwargs={"device": "cuda"}
)
vector_store = Chroma(
collection_name=COLLECTION_NAME,
embedding_function=instructor_embeddings,
persist_directory=PERSIST_DIRECTORY,
)
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
return RetrievalQA.from_chain_type(llm=local_llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)That’s all?” Sarah inquired, her eyebrows arched in surprise. “Indeed, that’s everything,” Mustafa confirmed with a nod.
Sarah’s eyes widened in amazement, “I must say, I’m quite taken aback by how few modifications were necessary!”
Mustafa chuckled lightly, giving her a playful wink, “Well, that’s also because our initial setup was so solidly constructed.”
There’s just one more order of business — deciding our course of action going forward.
Unfolding the Journey and Outlining the Path Ahead
In this article, we’ve embarked on a voyage through the universe of DocuVortex, unearthing the potential of language models in gleaning value from documents.
Embarking on a rainy demo day, our journey aimed to chart a new course from dependence on the OpenAI API to exploiting the untapped capabilities of local language models.
A critical pivot, this ensured the sensitive security content intrinsic to NeonShield’s operations remained strictly in-house, never breaching its confines to an external party.
Our guide, Mustafa, candidly shared his challenges, especially those linked to the complex infrastructure. His story was one of tenacity and resilience, weathering these trials with unwavering perseverance and invaluable assistance from the pen-test department.
We’ve steered our way from the initiation phase of installing requirements, meticulously traversed through document ingestion, and ultimately reached our destination with the final stage of document querying.
We’ve illuminated the slight yet significant modifications to the VortexPdfParser, VortexIngester, and VortexQuery classes, changes crucial for the integration of the Instructor_Transformer and TheBloke/wizardLM-7B-HF models.
The expedition has certainly seen its fair share of unexpected twists and turns. Yet, the adaptations required were minimal, a testament to the resilience and robustness of our original setup and the langchain library.
Despite the strides made, we’ve identified several areas ripe for improvement, including:
- Enhancing response time — one minute is not optimal.
- Investigating alternate, potentially superior, and larger models.
- Bolstering the robustness and flexibility of the ingest process.
- Examining the impact of variations in chunk size on improving quality.
In addition, Sarah astutely pointed out another path that warrants exploration: the potential to fine-tune the models.
While we’ve made substantial headway in wrapping up, the quest is far from concluded. There are uncharted territories to conquer, fresh challenges to overcome, and novel discoveries awaiting us.
We invite you to stay on board as we continue to push the frontiers of language models and document retrieval.
So, hold on tight; this is merely the prologue to a grand adventure!
As always, we believe in sharing our progress and lessons. We invite you to explore our project by visiting the associated GitHub repository.
Happy coding!



