Anthropic MCP: Extinguish Encoding Fires & Sleep Soundly
Build your own real-time DevOps assistant to slash troubleshooting time and keep our streaming service online

We process a ton of video encoding jobs for various clients. They send us their master content, and we encode it. Then, their customers stream the DRM-protected movies using our infrastructure.
Sounds easy, right? Not always.
Sometimes, these encoding jobs fail. We get the dreaded “error” status. Then comes the fun part: “Why did it fail?” As the guy who built the encoding workflow, that lands squarely on my shoulders.
Cue database diving, log file spelunking, and frantic Slack messages.
That’s when I discovered Anthropic’s Model Context Protocol (MCP) — think of it as a universal translator between AI models and your real-world systems.
Instead of struggling through database queries and log files at 2 AM, what if an AI assistant could access those systems directly, understand what went wrong, and explain it in plain English?
I decided to find out if MCP could turn those cryptic error messages into actionable solutions — and maybe let me sleep through the night for once.
You can find the complete source code for this project on GitHub and follow along as we explore how it works.
My “Aha!” moment with Anthropic’s MCP
Imagine this: 3 AM, and my phone lights up with another urgent message. “The client’s movie won’t encode. They need it online by morning.”
Our encoding workflow runs 24/7 in a Kubernetes cluster, processing huge production masters. We’re talking massive MXF files — sometimes 60GB or more. Our auto-scaling encoder usually handles the workload just fine.
But here’s the problem: it usually works once the encoding job starts. The real headaches are before encoding even begins — missing video tracks, audio without language tags, corrupted files — we’ve seen it all.
And because uploads take hours, we can’t give clients immediate feedback. They start the upload, create an order, and walk away. Later, they checked our management UI and saw the dreaded “error” status.
Then my phone buzzes. The error message? Something like “moov atom not found”. Try explaining that to someone who just wants their movie online!
That’s when it hit me. What if an AI could translate these technical errors into something humans actually understand?
When I discovered Anthropic’s Model Context Protocol (MCP), the lightbulb went off. I could give an AI assistant direct access to our error logs and encoding systems. Instead of me digging through database queries at 2 AM, Claude could do the heavy lifting.
Imagine turning “moov atom not found” into: “We found an issue with your source file’s structure. We’ll need you to provide a new copy of the original content.” That would be a game changer — not just for me but for our entire customer support team.
For the first time, I saw a way to break free from those 2 AM troubleshooting sessions. MCP was the missing piece that could connect Claude directly to our systems, giving him the context he needed to be truly helpful.
What is Anthropic’s Model Context Protocol (MCP)?
When I first heard about Anthropic’s MCP, I thought, ‘Great, another function-calling format to learn.’ If you’ve built AI tools before, you know the frustration — OpenAI wants JSON, this other LLM wants Python, and another wants some custom format. It’s like every AI speaks a different language.
But MCP isn’t just another way to call functions. It’s more like a universal translator for AI. Instead of building custom integrations for every language model, you build one MCP server that works with everything.
It’s the difference between learning ten languages versus having one really good interpreter.
Understanding MCP’s three core primitives
Think of MCP as organizing your AI’s capabilities into three simple buckets — like giving your AI assistant a well-organized workspace instead of a messy desk.
1. Resources
These are like reference materials that your AI can read but not change. Imagine handing your assistant a folder of important documents:
- Database schemas
- File contents
- User profiles
The key thing about resources is they’re passive — you decide what information to share, and the AI simply reads it. It’s added to the conversation as extra context, like saying “hey, keep these facts in mind as we talk.”
2. Tools
These are the actions your AI can take — the buttons it can push in your systems:
- Running database queries
- Calling APIs
- Sending emails
- Fetching real-time data
What makes tools special is that the AI decides when to use them based on what you’re discussing. It’s like giving your assistant access to specific applications but with guardrails. Most tools ask for your approval before they run, especially for actions that make permanent changes.
3. Prompts
Think of prompts as teaching your AI assistant how to approach different situations. They’re more than just templates — they’re the personality and expertise guidelines that shape how your AI responds. For example:
- Default behaviors: “You’re a video encoding expert. Use plain language. When you see technical errors, always explain what they mean for non-technical users.”
- Specialized roles: “You’re ‘EncodingHelper’. You translate technical errors into customer-friendly language and suggest specific next steps.”
- Task instructions: “When preparing customer emails about encoding failures, include: 1) What happened in simple terms, 2) Why it matters, and 3) Exactly what they need to do next.”
The beauty of prompts is they ensure consistent, high-quality responses without you having to repeat the same instructions over and over. It’s like training your assistant once and having them remember exactly how you like things done.
Why this separation matters
This clean separation is what makes MCP so powerful. Instead of jumbling everything together:
- Resources give your AI knowledge (“Here’s what you need to know”)
- Tools give your AI abilities (“Here are things you can do”)
- Prompts give your AI guidance (“Here’s how to approach this task”)
The result? Your AI can access real-world data more accurately, with fewer hallucinations. It knows the difference between information it has versus actions it can take.
Over 700 MCP servers are already in the wild, showing developers embracing this approach.
But here’s the catch — for MCP to reach its full potential, the major players like OpenAI, Google, and Meta would need to adopt it. It’s open-source, so they could. Until then, MCP’s greatest value will be within Anthropic’s ecosystem.
That said, even if it doesn’t become the universal standard, the design patterns MCP introduces are incredibly valuable for thinking about how AI should interact with your systems. You’ll become a better AI developer just by understanding its principles.
Building an encoding workflow DevOps assistant
Ready to build your own encoding workflow assistant that actually works at 3 AM? I’ll walk you through exactly how I did it — no complicated jargon, just practical steps that saved my sleep schedule and my sanity.
Let me show you the exact setup that turned those cryptic ‘moov atom not found’ errors into plain English solutions.
Clarifying my approach
Before writing a single line of code, I hit my first roadblock: MCP’s terminology was confusing me. Should my email templates be “resources” or “prompts”? Is getting job status a “tool” or a “resource”? After some coffee-fueled experimentation, here’s the practical breakdown that finally clicked for me:
- Prompts: Think instruction manuals for Claude (like “You are an video encoding expert”)
- Resources: Reference materials Claude can read (like “here’s our email template for a failed encoding job”)
- Tools: Actions Claude can take (like “here’s how to look up a job status”)
These distinctions might seem subtle, but they significantly impact how the assistant interacts with both users and external systems.
My use case: Turning 3 AM panics into 30-second fixes
My assistant addresses a common pain point: handling failed encoding jobs. Here’s the workflow I designed:
- The trigger: My phone buzzes with a service desk message: “Help! Job XYZ-123 failed, and the client is freaking out!”
- The conversation: Instead of diving into database queries and log files, I simply ask Claude: “What’s wrong with job XYZ-123?”
- Behind the scenes: Claude uses an MCP tool to pull the job’s status and that cryptic error message only engineers understand
- The translation: Claude turns “moov atom not found” into something actually helpful: “The source file has an incompatible format structure. The client needs to upload a new master file.”
- Quick response: I ask Claude to “draft an email to the client about this issue,” and it creates a perfect, professional message using my email template
- One-click action: Claude opens my email client with everything pre-filled, ready for a quick review, and send
I deliberately kept a human in the loop for this first version. The assistant drafts everything, but I still review and send the emails myself.
This gives me confidence in the system while saving 90% of my troubleshooting time.
Next versions will bring the service desk team into the mix, and eventually, we’ll automate the whole process for truly hands-off operations.
Architecture: The blueprint that makes it all work
Let’s break down how all the pieces fit together — no fancy jargon, just the stuff that matters:
Picture three main building blocks working together to solve your 3 AM encoding nightmares:
- Your conversation partner: Claude Desktop
This is simply where you chat with Claude — the friendly face that understands your questions about failed encoding jobs and responds in plain English. - The brains of the operation: MCP Server
Built in Python, this behind-the-scenes powerhouse connects Claude to your actual work systems. It’s like Claude’s personal assistant that knows how to look up technical stuff for you. - The real-world connections: Integration Points
- Encoding system: Reaches into your workflow via REST API to fetch job statuses and error details
- Movie database: Talks to OMDB to pull in helpful context about the content (super useful for client communications!)
- Your email: Opens your desktop email client with pre-written explanations when you need to update clients
Here’s what it looks like in action:
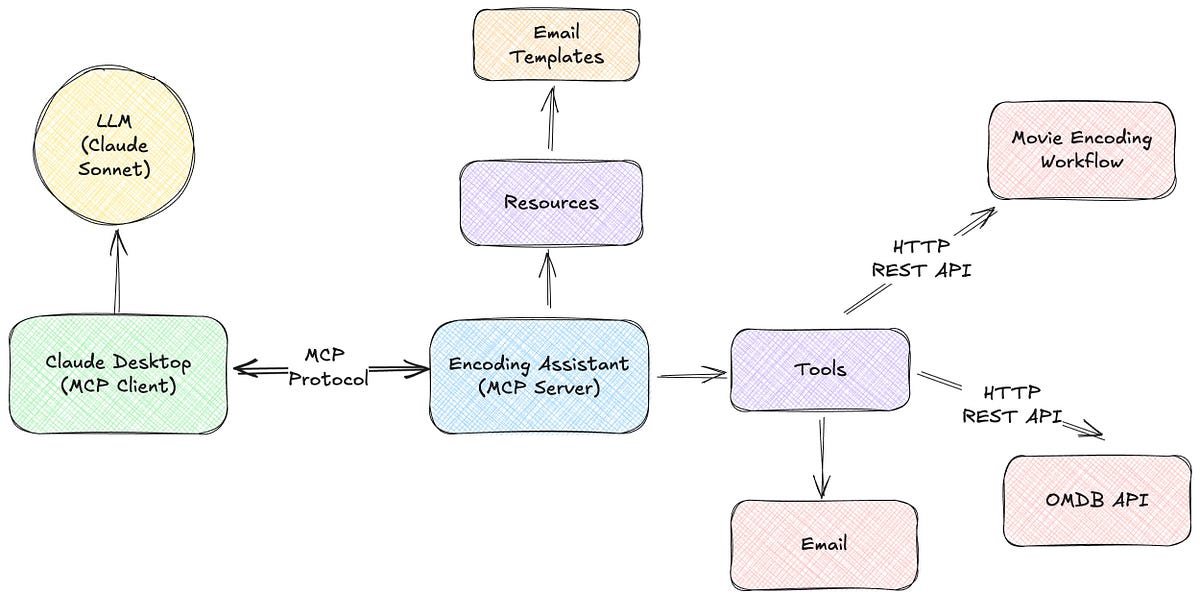
What makes this setup so powerful? Each piece does one job really well, and they all talk to each other seamlessly. When you ask about a failed job, Claude doesn’t pretend to know the answer — it looks it up in real time, pulls in the right context, and gives you exactly what you need.
And the best part? You can start small with just one connection (like the encoding system) and add the others as you go. I built this incrementally, seeing value at each step rather than waiting for the “perfect” complete system.
Why Python for the MCP server? It just works
“Could I use JavaScript or Java for this?” Sure, but let me tell you why Python was my go-to choice for getting this up and running quickly:
- It handles the chaos beautifully — When five encoding jobs fail at once, Python’s async support handles all those simultaneous requests without breaking a sweat. No more “sorry, I’m busy” messages when you need answers fast.
- Integration is a breeze — Need to connect to your workflow API? There’s a Python library for that. Database lookups? Email systems? Movie metadata services? Python’s ecosystem has your back with mature, well-documented libraries for practically everything.
- The MCP protocol feels natural — The Python SDK for MCP maps perfectly to how the protocol actually works. It’s almost like the MCP spec was written with Python in mind (even though it wasn’t).
- Resource management that doesn’t leak — The lifespan feature in SDK 1.3.0 RC1 is a lifesaver for long-running services. It properly starts up and closes down connections, so your server won’t slowly bleed resources over days of operation.
Could I have used Node.js, TypeScript, or Java? Absolutely. But Python let me go from concept to working prototype in a single afternoon. When you’re building something to solve real problems (and get some sleep), that kind of productivity is priceless.
If you’re comfortable with another language, don’t let me stop you — the MCP spec is language-agnostic. But if you want the path of least resistance, Python’s your friend here.
Setting up the development environment
Getting started with MCP development requires a few key steps. Here’s what worked for me:
- Install the right dependencies: I used Python’s
uvpackage manager for faster, more reliable dependency management - Register your MCP server: The
mcp installcommand registers your server with Claude Desktop - Use development mode: The
mcp devcommand starts the MCP Inspector, a helpful tool for debugging
# Install your server with Claude Desktop
uv run mcp install ./src/encoding_devops/main.py
# Start in development mode with the inspector
uv run mcp dev ./src/encoding_devops/main.pyThe MCP Inspector was particularly helpful during development. It provides a web interface (http://localhost:5173) that lets you:
- Browse your server’s resources, prompts, and tools
- Test tools directly without going through Claude
- Debug any issues with your implementations

This development workflow streamlined the process of building and refining my assistant, allowing me to iteratively improve each component before integrating it into the full system.
In the next section, I’ll dive deeper into the code implementation and show you exactly how I set up the server and defined the tools and resources that make this assistant work.
Diving into the code (But not too deep!)
Let’s take a practical look at how I built this encoding workflow assistant with MCP. I’ll share key code snippets and explain the architecture decisions without drowning you in implementation details.
Setting up the MCP server
First, I created an MCP instance that serves as the foundation of our assistant:
# From mcp_instance.py
mcp = FastMCP(
“encoding-manager”,
lifespan=server_lifespan,
dependencies=[“aiohttp”, “python-dotenv”, “loguru”, “cachetools”]
)The lifespan context manager is important — it initializes our API clients when the server starts and cleans them up when it shuts down:
@asynccontextmanager
async def server_lifespan(server: FastMCP) -> AsyncIterator[AppContext]:
"""Manage server startup and shutdown lifecycle with type-safe context"""
logger.info("Initializing server lifespan")
client = EncodingClient()
omdb_client = OMDBClient()
try:
logger.debug("Initializing client sessions")
await client.init_session()
await omdb_client.init_session()
logger.info("Server lifespan initialized successfully")
yield AppContext(client=client, omdb_client=omdb_client)
finally:
logger.debug("Cleaning up server lifespan")
await client.close_session()
await omdb_client.close_session()
logger.info("Server lifespan cleanup completed")This pattern ensures our resources are properly initialized and cleaned up, which is crucial for a production application. The lifespan pattern makes the shared clients available throughout the application’s lifetime.
Note, however that the lifespan context manager is introduced in the 1.3.0 Release Candidate of the MCP Python SDK.
Defining tools for Claude desktop
The heart of our implementation lies in the tools that Claude can access to gather information and take action. Here’s how I implemented the job retrieval tool:
@mcp.tool()
async def get_job_by_name(name: str, ctx: Context) -> str:
"""Get details of an encoding job by its name"""
app_ctx: AppContext = ctx.request_context.lifespan_context
job_data = await app_ctx.client.get_job_by_name(name)
return job_dataBy adding the @mcp.tool() decorator from the SDK you tell to the MCP server that you want to expose this function to the MCP server. Also notice that the tool function takes a Context parameter. This gives the function access to our API clients through the lifespan context we set up earlier.
@dataclass
class AppContext:
"""Application context with initialized resources"""
client: EncodingClient
omdb_client: OMDBClientIntegrating with external APIs
For the OMDB integration, I implemented a simple client with caching to improve performance. This adds context to encoding jobs by providing information about the content being processed:
@mcp.tool()
async def search_movie(title: str, ctx: Context) -> str:
"""
Search for a movie by title
Args:
title: Movie title to search for
Returns:
String representation of the search results
"""
app_ctx: AppContext = ctx.request_context.lifespan_context
results = await app_ctx.omdb_client.search_movie(title)
return {
"query": title,
"total_results": int(results.get("totalResults", 0)),
"movies": results.get("Search", [])
}The caching layer is particularly important for development and testing, as it reduces unnecessary API calls and speeds up response times.
# Create a TTL cache for movie searches
_movie_cache = TTLCache(maxsize=100, ttl=3600) # Cache for 1 hour
@cached(_movie_cache)
async def search_movie(self, title: str, page: int = 1, type_filter: str = "movie") -> dict:
"""
Search for movies by titleCreating useful resources
I also defined some resources for common tasks like drafting emails about encoding issues:
@mcp.resource("email://draft-email-redeliver-encoding-job/{job_name}/{client_name}")
def email_redeliver_encoding_job(job_name: str | None = None, client_name: str | None = None) -> str:
"""
Returns a draft email to request content redelivery for an encoding job.
"""
return f"""Subject: Content Redelivery Request - {job_name}
Dear {client_name},
I hope this email finds you well. I am writing regarding your encoding job "{job_name}".
We have encountered some issues with the source content for this job and need to request a redelivery
of the original materials. This will help ensure we can process your encoding job successfully.
# … rest of the email template …These resources are helpful for customer communication, ensuring consistent and professional messaging while saving time.
What about error handling?
Error handling is critical for a reliable assistant. The EncodingClient includes token refresh logic and proper session management:
async def ensure_token(self):
"""Ensure we have a valid access token"""
if not self.token or (self.token_expiry and datetime.now() >= self.token_expiry):
await self.refresh_token()Each API call is wrapped with proper error handling to ensure the assistant remains responsive even when things go wrong.
The main application entry point
Finally, the main.py file ties everything together, loading environment variables and starting the MCP server:
async def main():
"""Entry point for the MCP server"""
try:
load_environment()
await run_server()
except Exception as e:
logger.error(f"Server error: {e}")
sys.exit(1)This modular design makes the code easy to maintain and extend as your needs evolve.
What I learned (and what surprised me)
When I first jumped into MCP, I felt completely lost trying to understand the difference between Prompts, Resources, and Tools. After some late-night coding sessions (and plenty of coffee), here’s how it finally clicked for me:
- Prompts: Give the model instructions on how to respond. Think of them as guidance or default settings.
- Resources: External data that the model uses for context.
- Tools: Functions the model can call to perform actions or get new data.
I was genuinely impressed with how MCP transforms cryptic error messages into something that actually makes sense. No more staring at “moov atom not found” and wondering what went wrong!

One small annoyance — you’ll see a permission popup every single time a tool runs. Great for security, absolutely, but after the twentieth time approving the same tool, you’ll be wishing for a “just trust this” option. Maybe in a future update?

The coolest part was how quickly I could expand the system. Once I had the basic framework, adding new tools felt like playing with LEGO blocks. “Let’s connect to OMDB to pull movie data! Now, let’s add email automation! Why not Jira integration?” Before I knew it, I had built something genuinely useful.
And stability? Rock solid. Unlike OpenAI’s function calling (which randomly failed about 5% of the time), every single MCP tool call worked perfectly. That reliability alone makes it worth exploring.
MCP: A simpler way to build smart AI?
Imagine giving your AI a neat, organized desk instead of dumping everything in one chaotic pile. That’s what MCP does.
- Prompts: What you ask the AI.
- Resources: Extra info the AI can use (like data from a spreadsheet).
- Tools: Actions the AI can take (like sending an email).
It’s like giving your AI assistant its own workspace with labeled drawers instead of a messy desk where nothing can be found. You’re in control — swap out information, add new abilities, all without the AI getting confused about what’s what.
Think of it as using sticky notes — one for each specific task or piece of information. Clean, clear, and exactly where it belongs.
Why should you care?
- You’re in charge: Change how your AI behaves without starting from scratch every time
- Real-world connection: Your AI can actually DO things — check databases, send emails, whatever you need
- No more spaghetti code: Keep your AI projects organized so you (and others) can understand them
- See what’s happening: No more mysterious black-box behavior — you know exactly what your AI can access and do
Jump in and try it!
Don’t just nod along — try MCP in your next project!
Start super simple. Maybe add a calculator tool, so your AI can do math or connect it to a weather API. Even these tiny additions will show you how powerful the approach is.
Once you see it working, you’ll want to add more.
Will this become the standard?
Here’s the honest truth: For MCP to become universal, the big players like OpenAI, Google, and Meta need to adopt it. It’s open-source, so they could — but until they do, you’ll get the most mileage using it with Claude Desktop or any other open-source MCP client and servers.
But don’t worry! There’s already movement happening — other MCP clients and servers are popping up. For example.
- oterm — A text-based terminal client for Ollama has support for MCP servers. This lets you connect your MCP server to Ollama.
- Cline — The coding agent now has a marketplace for MCP servers.
- Cursor — Has support for MCP servers
Even if it doesn’t become the standard, the core ideas will change how you think about AI systems. It’s about creating cleaner boundaries between information, instructions, and actions.
What to do right now
- Check Anthropic’s docs: Get the details straight from the source
- Build something small: Even a tiny project will teach you more than just reading about it
- Share your creation: Got something working? Put it on GitHub and show others!
- Look at the Encoding DevOps source: The source is available GitHub for inspiration
MCP isn’t just a technical spec — it’s a whole new way to think about how AI should work with our world. Mix and match prompts, tools, and resources to create something that solves real problems.

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories.
Subscribe to our newsletter and YouTube channel to stay updated with the latest news and updates on generative AI. Let’s shape the future of AI together!




